
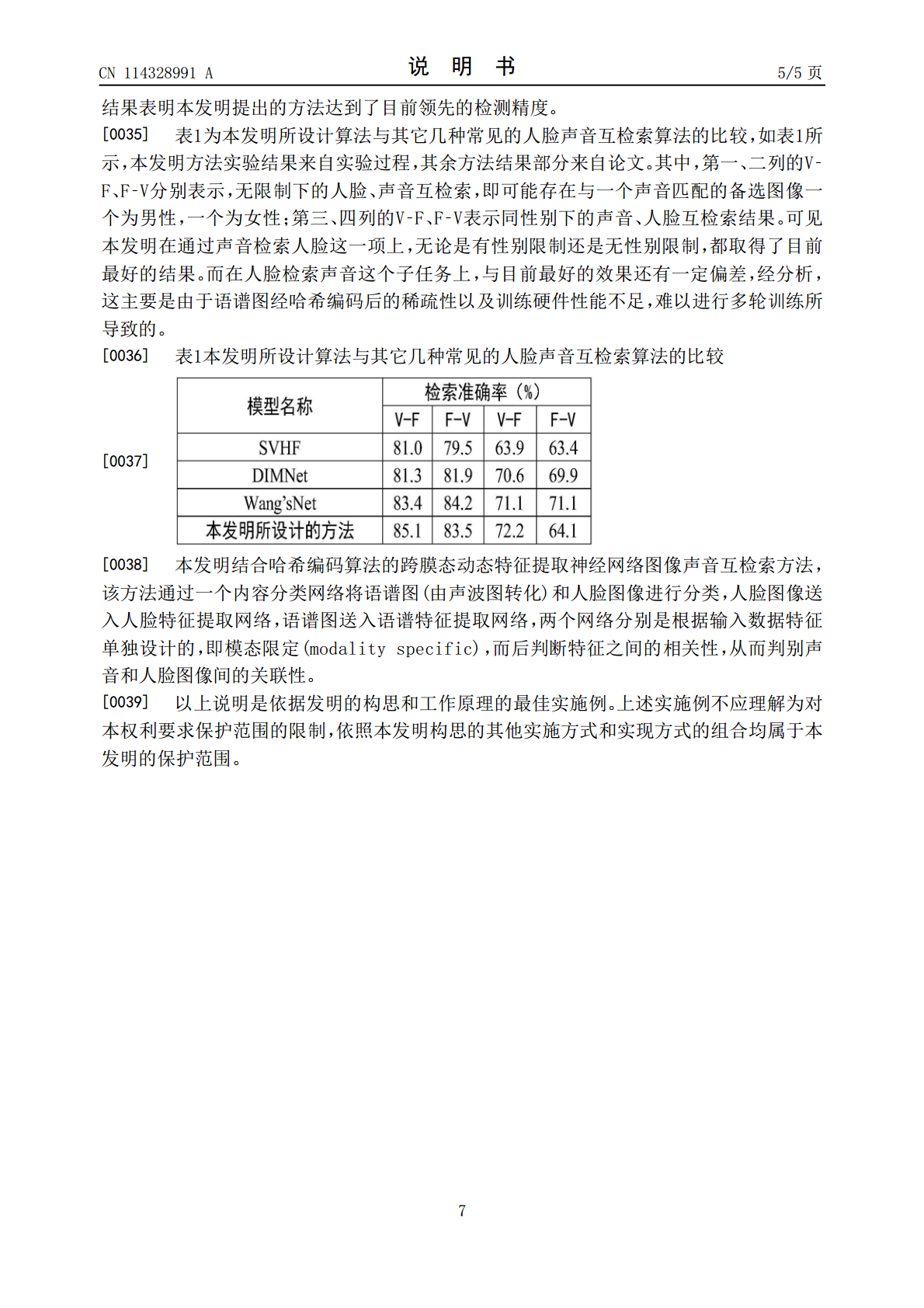
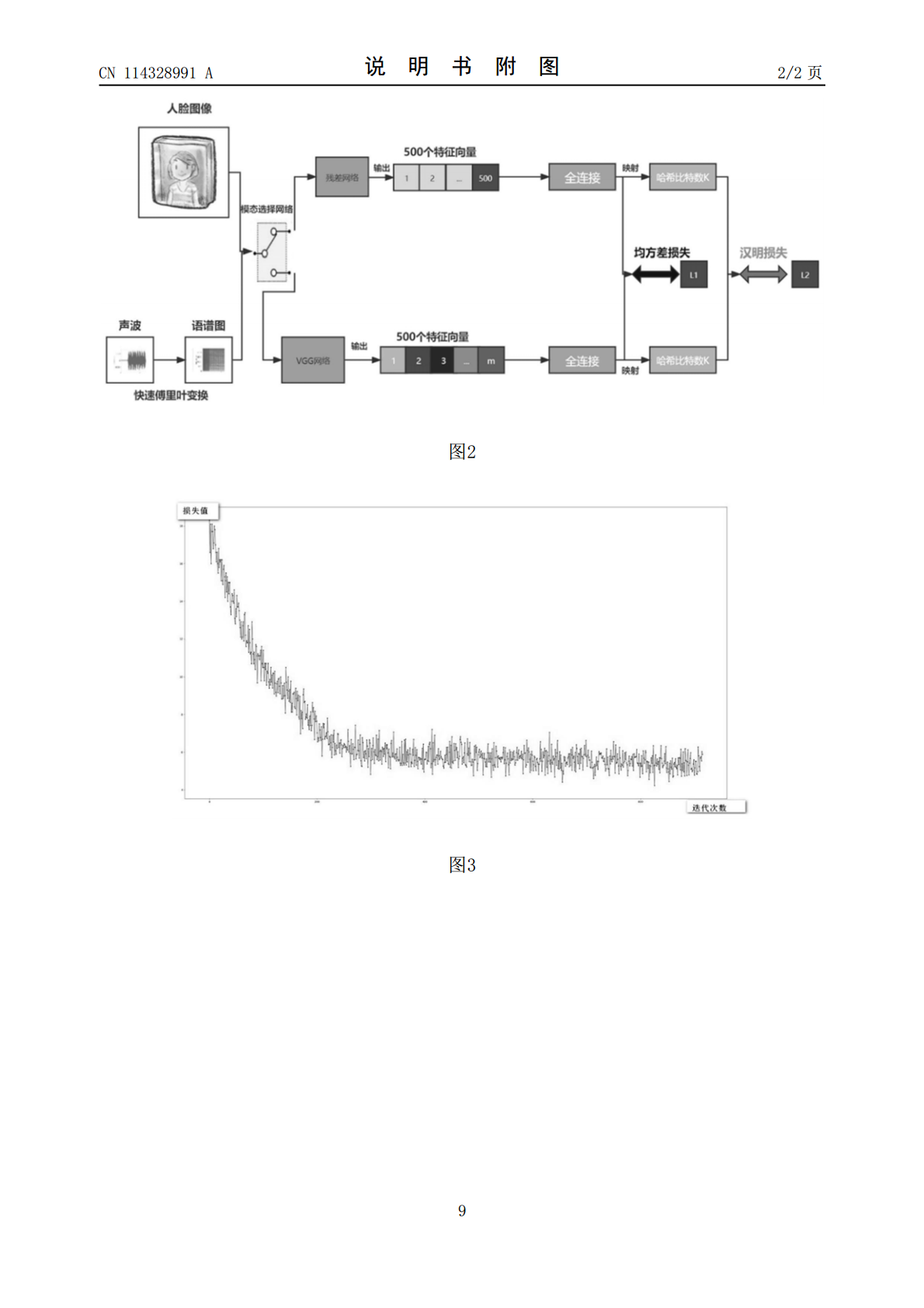
一种基于哈希编码的图像声音检索方法.pdf

雨巷****莺莺


1/9

2/9

3/9

4/9

5/9

6/9
7/9

8/9
9/9
在线预览结束,喜欢就下载吧,查找使用更方便
相关资料

一种基于哈希编码的图像声音检索方法.pdf
一种基于哈希编码的图像声音检索方法。在预处理阶段,首先将声音通过快速傅里叶变换转化为语谱图,同时对转化后的语谱图以及原始的人脸图像进行旋转、对比度变换等数据增强操作;在训练阶段,将之前处理好的人脸图像以及语谱图传入一个经由ImageNet预训练的基于内容分类的神经网络中,自动将人脸和语谱图传递到各自模态的特征提取网络中。相比于传统方法,哈希编码大幅降低了检索消耗的时间,提升了系统执行效率;同时,对语谱图进行对比度增强可以抑制低频噪声,以及采用一个基于内容的样本分类器可以减少人为区分样本出错的概率,本方法在

基于哈希编码学习的图像检索方法.docx
基于哈希编码学习的图像检索方法标题:基于哈希编码学习的图像检索方法摘要:图像检索技术在当今的信息时代中扮演着重要的角色,可以快速准确地从大规模的图像集合中检索到用户感兴趣的图像。然而,随着图像数据的快速增长,传统的图像检索方法面临着检索速度慢、存储空间大以及检索精度低的问题。为了解决这些问题,哈希编码学习技术逐渐成为图像检索领域的研究热点。本文将介绍基于哈希编码学习的图像检索方法,并讨论其优缺点及未来的研究方向。一、引言随着互联网和数码相机的普及,图像数据的数量呈现爆发式增长。面对如此大量的图像数据,如何

一种利用基于深度语义排序哈希编码的图像检索方法.pdf
本发明公开了一种利用基于深度语义排序哈希编码的图像检索方法,该方法包括以下步骤:将多标签图像数据集中的部分图像作为训练集,剩下的图像作为图像测试集;使用深度卷积神经网络来构建深度哈希函数;根据图像的多标签信息,构建出图像间的语义相似度排序;以基于三元组的代理排序损失函数做为实际的模型目标函数,并使用随机梯度下降法来优化深度哈希函数;用学习到的深度哈希函数计算图像的哈希码,通过计算测试图像的哈希码与训练集中每一个图像的哈希码之间的汉明距离来检索图像。本发明方法能够保留多标签图像在语义空间中的多级相似度,并且

基于哈希编码的大规模图像检索方法研究的开题报告.docx
基于哈希编码的大规模图像检索方法研究的开题报告一、研究背景图像是一种重要的多媒体数据,它被广泛地应用于许多领域中,如人脸识别、视觉监控、医学影像分析、搜索引擎等。随着互联网的快速发展和数字化技术的不断进步,大量的图像数据被产生和存储,如何有效地管理和检索这些大规模的图像数据成为了一个急需解决的问题。哈希编码(hashing)是一种快速的图像检索方法,其主要思想是将高维的图像数据映射成低维的二进制编码,从而大大降低了存储和计算的复杂度。哈希编码方法具有速度快、内存占用小和可扩展性强等优点,在大规模图像检索中

基于哈希编码的大规模图像检索方法研究的任务书.docx
基于哈希编码的大规模图像检索方法研究的任务书任务书一、背景随着数字图像的快速增长,如何快速、准确地找到图像库中的相似图像成为了图像检索领域的重要研究课题。传统的相似图像检索方法通常基于图像的特征向量来进行匹配,但针对大规模图像库,这种方法需要耗费大量的时间和计算资源。因此,基于哈希编码的大规模图像检索方法成为了研究热点。二、任务本次研究任务旨在:1.研究哈希编码的原理和算法,掌握其在大规模图像检索中的应用。2.实现一种基于哈希编码的图像检索算法,并与传统的特征向量匹配方法进行比较分析。3.针对实验中存在的