
一种基于FHGAN的高保真语音增强模型及其应用.pdf

玄静****写意


1/10

2/10

3/10

4/10

5/10

6/10

7/10

8/10

9/10

10/10
亲,该文档总共18页,到这已经超出免费预览范围,如果喜欢就直接下载吧~
相关资料

一种基于FHGAN的高保真语音增强模型及其应用.pdf
本发明提供一种基于FHGAN的高保真语音增强模型及其应用,高保真语音增强模型是将端到端的FFTNet模型与生成对抗网络结构相结合,添加PFPLoss引导生成器建模,利用HiFi‑GAN多尺度对抗判别器,并与SE‑FFTNet生成器匹配,在时域和频域上提取深度特征匹配损失,结合适用的目标函数在生成对抗网络机制下平衡学习,得到的FHGAN模型即为所述高保真语音增强模型。本发明在基线模型SE‑FFTNet、HiFi‑GAN的基础上提出FHGAN网络,能够可大大降低模型的计算复杂度、有效区分噪声和干净语音,还原增

高保真语音装置.pdf
本发明提供一种语音保真装置,包括主话筒、声源话筒及处理电路,主话筒用以接收语音并产生主信号;声源话筒用以接收来自用户声源的振动并产生声源信号;处理电路用以接收所述主信号及所述声源信号,将两者相加并进行衰变后得到保真信号,由此实现高传真的语音播放。

语音增强模型生成方法和装置、语音增强方法和装置.pdf
本申请公开了一种语音增强模型生成方法和装置,涉及语音技术、计算机视觉、深度学习技术领域。该方法的一个具体实施方式包括:获取样本语音信号的样本时频域谱图集,样本时频域谱图集包括至少一个样本时频域谱图;获取预先建立的深度神经网络,深度神经网络包括:平滑模块、网络模块,平滑模块用于对输入的图像进行平滑处理,得到平滑特征图;执行以下训练步骤:从样本时频域谱图集中选取样本时频域谱图,并将选取的样本时频域谱图以及与选取的样本时频域谱图对应的平滑特征图同时输入网络模块;响应于确定深度神经网络满足训练完成条件,则将深度神

语音增强模型训练方法、语音增强方法、相关设备及介质.pdf
本公开关于一种语音增强模型训练方法、语音增强方法、相关设备及介质。训练方法包括:基于三维声场麦克风采集的三维扫频信号,确定三维房间冲激响应;将单通道纯净时域语音信号和时域噪声信号分别与三维房间冲激响应进行卷积,得到纯净时域三维语音信号和时域三维噪声信号;基于预设信噪比对纯净时域三维语音信号和时域三维噪声信号进行混合处理,得到样本含噪时域三维语音信号;将样本含噪时域三维语音信号的复数谱输入到语音增强模型中,得到单通道预估增强复数谱;基于单通道预估增强复数谱对应的预估时域信号和单通道纯净时域语音信号,确定语音
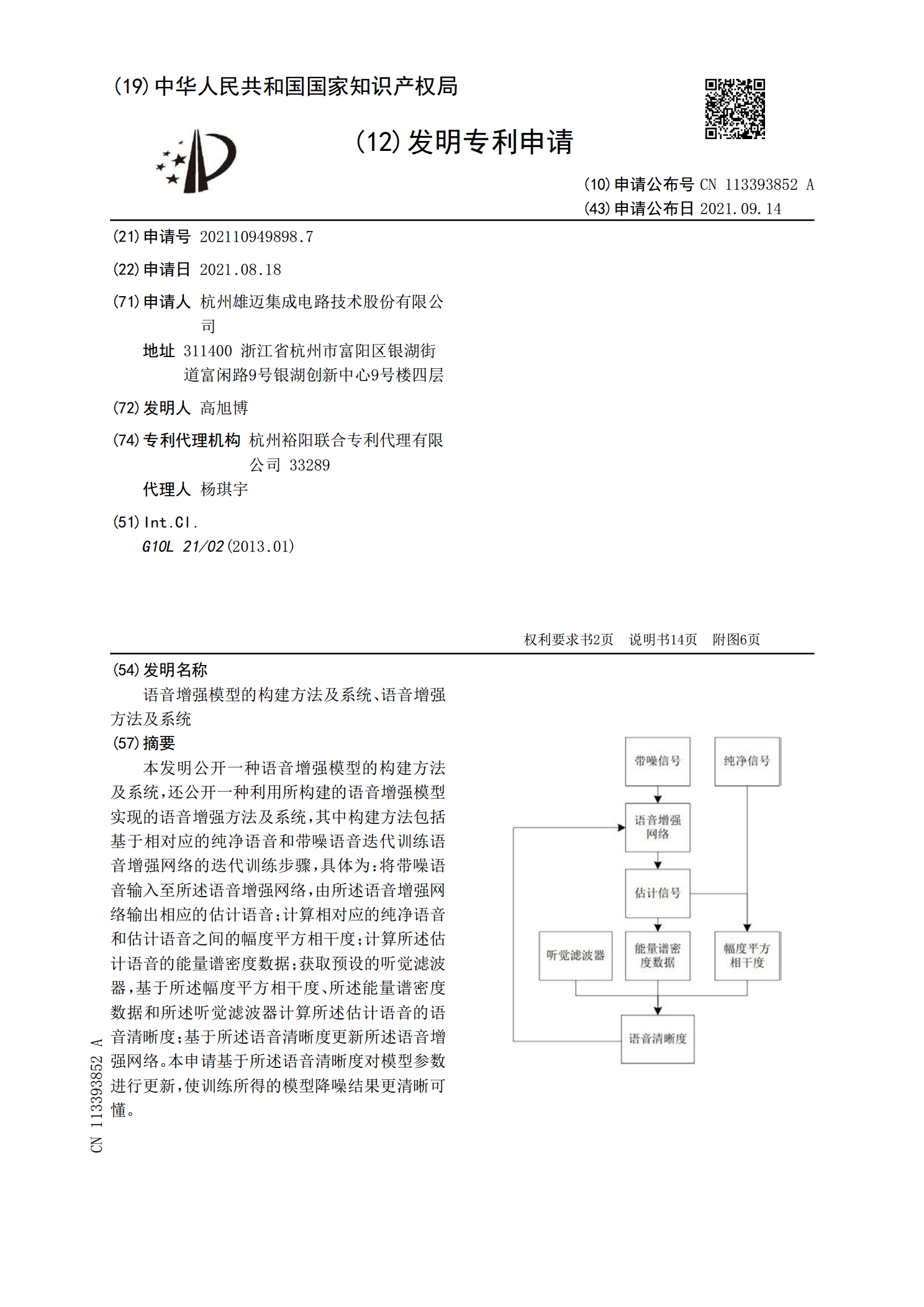
语音增强模型的构建方法及系统、语音增强方法及系统.pdf
本发明公开一种语音增强模型的构建方法及系统,还公开一种利用所构建的语音增强模型实现的语音增强方法及系统,其中构建方法包括基于相对应的纯净语音和带噪语音迭代训练语音增强网络的迭代训练步骤,具体为:将带噪语音输入至所述语音增强网络,由所述语音增强网络输出相应的估计语音;计算相对应的纯净语音和估计语音之间的幅度平方相干度;计算所述估计语音的能量谱密度数据;获取预设的听觉滤波器,基于所述幅度平方相干度、所述能量谱密度数据和所述听觉滤波器计算所述估计语音的语音清晰度;基于所述语音清晰度更新所述语音增强网络。本申请基