
一种基于注意力机制Seq2Seq多标签简历的行业分类方法及系统.pdf

一吃****福乾


1/10

2/10

3/10

4/10

5/10

6/10

7/10

8/10

9/10
10/10
亲,该文档总共11页,到这已经超出免费预览范围,如果喜欢就直接下载吧~
相关资料

一种基于注意力机制Seq2Seq多标签简历的行业分类方法及系统.pdf
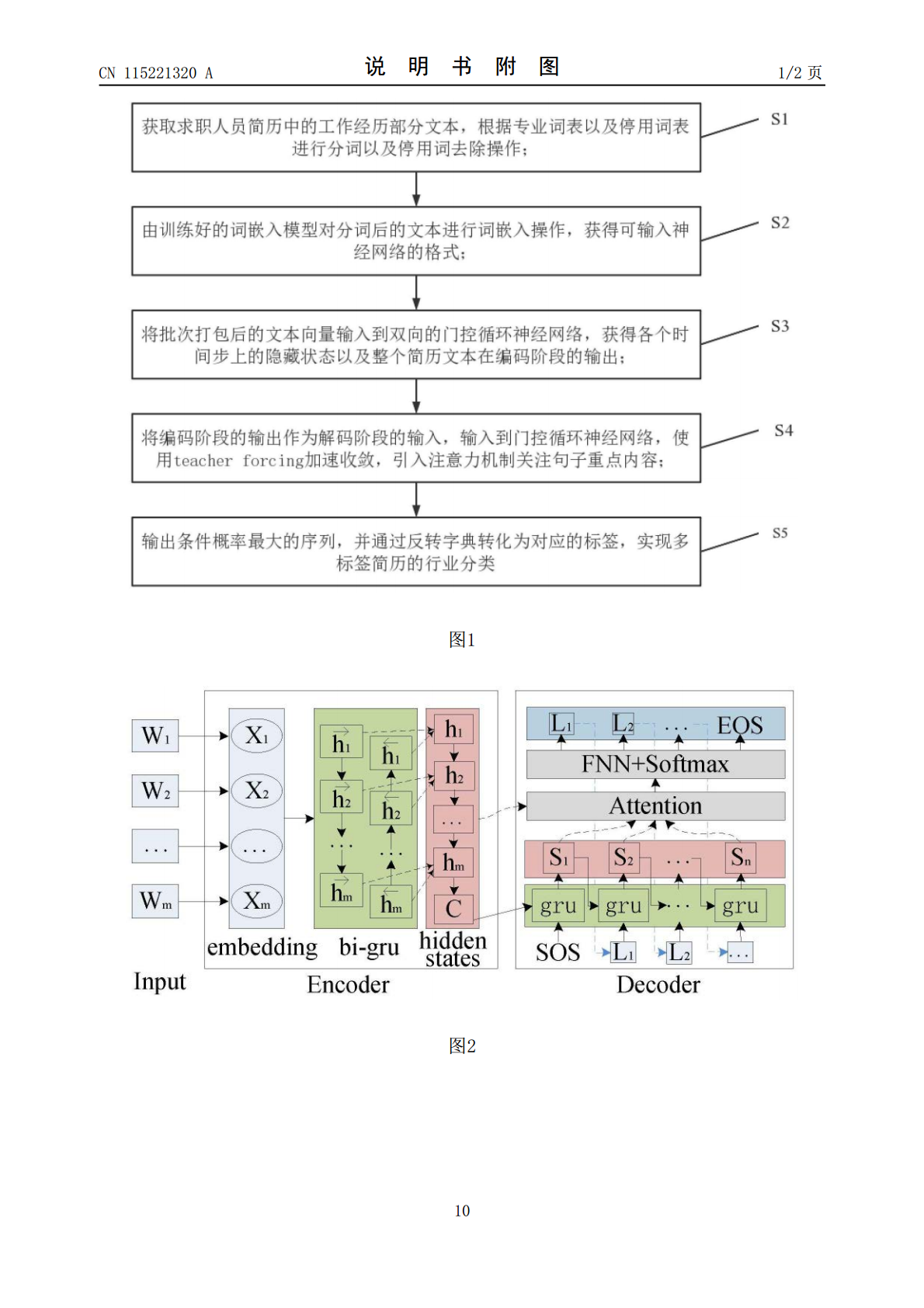
本发明公开了一种基于注意力机制Seq2Seq多标签简历的行业分类方法及系统,分类方法包括:获取求职人员简历文本,进行分词与停用词去除操作;由文本序列字典,将词语转化为对应的序列后经过词嵌入操作,将词语向量化,获得简历文本的向量表示;对输入文本各个时间步上的词语提取隐藏状态,获得包含上下文语义的向量编码;解码过程中引入注意力机制,使得每个时间步的输出关注输入时的不同内容,实现多标签输出;获取输出中概率最大作为最终的输出序列,通过反转字典,将输出序列转化为预测的各行业标签,实现多标签简历的行业分类。本发明可以

一种基于注意力机制的多标签文本分类方法及系统.pdf
本发明提出一种基于注意力机制的多标签文本分类方法及系统,涉及多标签文本分类的技术领域,解决了当前多标签文本分类方法大多忽略标签与文本之间关联性,在标签规模大,类别分布不均衡时,分类准确率低的问题,基于图嵌入算法优化标签之间的相似度,得到标签结构矩阵,保留标签的全局结构和局部结构,再通过构建基于卷积神经网络和注意力机制的多标签文本分类模型,利用卷积神经网络进行文本深层的特征提取,利用注意力机制捕获标签结构与文档内容的潜在关系,进行了更深层次的挖掘,能在标签规模大、标签分布不均衡的情况下,充分利用训练集中的标

基于对比学习增强双注意力机制的多标签文本分类方法.docx
基于对比学习增强双注意力机制的多标签文本分类方法目录一、内容概览................................................2二、相关工作................................................31.多标签文本分类研究现状................................42.注意力机制在文本分类中的应用..........................53.对比学习在文本分类中的研究...............

一种基于注意力机制的多标签稀疏对抗攻击方法.pdf
本发明公开了一种基于注意力机制的多标签稀疏对抗攻击方法,属于对抗攻击技术领域,该攻击方法具体步骤如下:(1)采集标签图像并进行处理;(2)构建深度学习网络以进行分析对抗;(3)实时监测该学习网络运行情况并进行优化;(4)反馈并存储数据以供工作人员查看调整;本发明能够对深度学习网络进行多次的迭代训练,大幅提高深度学习网络对标签图像分析的准确性,无需工作人员手动进行训练,减少工作人员工作量,提高工作人员工作积极性,能够更直观的将深度学习网络运行性能反馈给工作人员查看,方便工作人员对深度学习网络运行情况进行分析

基于标签推理和注意力融合的多标签文本分类方法.pptx
汇报人:CONTENTSPARTONEPARTTWO标签推理的原理注意力融合的原理标签推理和注意力融合结合的原理PARTTHREE多标签文本分类的背景和意义多标签文本分类的方法和技术基于标签推理和注意力融合的多标签文本分类方法的提出PARTFOUR标签推理的实现注意力融合的实现结合标签推理和注意力融合的方法实现PARTFIVE实验数据集介绍实验设置和参数调整实验结果展示结果分析和讨论PARTSIX基于标签推理和注意力融合的多标签文本分类方法的优势和贡献未来研究方向和展望汇报人: