
机器学习与数据挖掘复习.pdf

文库****品店


1/10

2/10

3/10

4/10

5/10

6/10

7/10

8/10
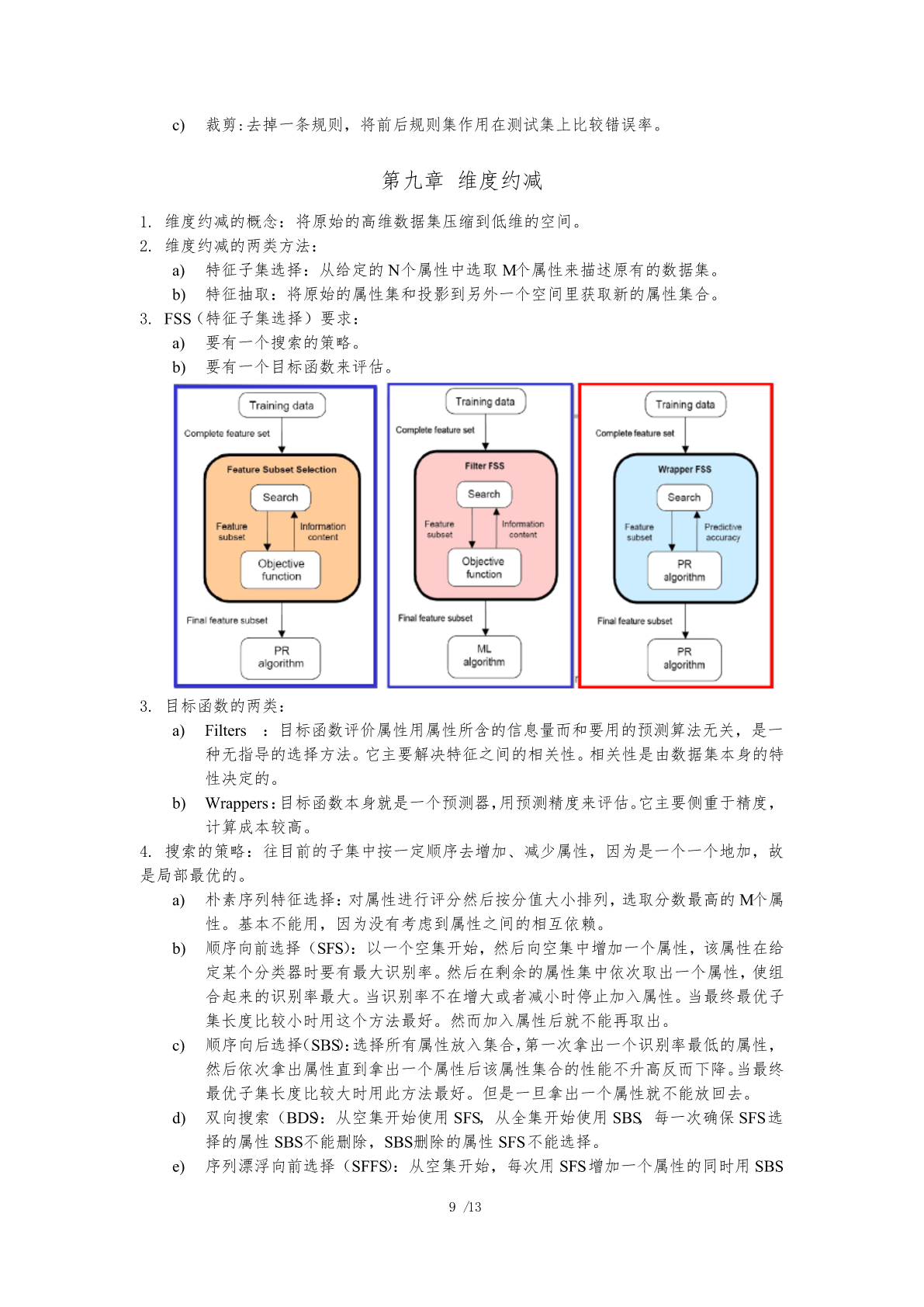
9/10

10/10
亲,该文档总共13页,到这已经超出免费预览范围,如果喜欢就直接下载吧~
相关资料

机器学习与数据挖掘复习.pdf
机器学习与数据挖掘复习第一章:Introduction1.什么是数据挖掘:数据挖掘时从大量的数据中取出令人感兴趣的知识(令人感兴趣的知识:有效地、新颖的、潜在有用的和最终可以理解的)。2.数据挖掘的分类(从一般功能上的分类):a)描述型数据挖掘(模式):聚类,summarization,关联规则,序列发现。b)预测型数据挖掘(值):分类,回归,时间序列分析,预测。3.KDD(数据库中的知识发现)的概念:KDD是一个选择和提取数据的过程,它能自动地发现新的、精确的、有用的模式以及现实世界现象的模型。数据挖掘

机器学习与数据挖掘.ppt
自然模型社会的需求历史的故事线性感知机20世纪70年代面临的选择AI20世纪80年代面临的选择统计机器学习维数灾难概率图模型一、表示二、推断三、学习表示---I-map求解Bayes问题的策略推断---Bayes问题学习学习结构的两种策略历史进程---20年河东,20年河西?总结:我们的纠结前途:“预测”与“描述”谢谢

机器学习与数据挖掘.ppt
机器学习与数据挖掘何为机器学习、数据挖掘?何为机器学习、数据挖掘?何为机器学习、数据挖掘?何为机器学习、数据挖掘?何为机器学习、数据挖掘?何为机器学习、数据挖掘?何为机器学习、数据挖掘?何为机器学习、数据挖掘?何为机器学习、数据挖掘?何为机器学习、数据挖掘?机器学习与数据挖掘研究内容机器学习与数据挖掘研究内容机器学习与数据挖掘研究内容

机器学习与数据挖掘技术综述.pdf
机器学习与数据挖掘技术综述随着信息时代的到来,以及互联网和移动设备的普及,我们生活在的世界正在发生巨大变化。数据的增长速度越来越快,数据的价值也越来越高。如何从这些海量数据中挖掘出有价值的信息,成为了重大挑战之一。机器学习和数据挖掘技术正是帮助我们应对这个挑战的有效工具。一、机器学习技术机器学习是人工智能领域的主要分支之一。机器学习的目标是使计算机具有自我学习的能力,即通过对大量数据的分析和总结来学习一些规律和模式,从而对未来的数据进行预测和分类。机器学习可以分为监督学习、无监督学习和强化学习三种。1.监

《数据挖掘与机器学习》课程教案.pdf
《数据挖掘与机器学习》课程教案(首页)课程总学时:72学课程/项目数据挖掘与机器学习名称学分3时理论:54学时课程课程类别:专业必修■专业必修口公共必修□公共选修实验:18学时授课教师***授课专业大数据技术与应用授课班级教学本课程的主要目的是培养学生的数据挖掘与机器学习的理论分析与应用实践的目的和要综合能力。通过本课程的教学,使学生掌握数据挖掘和机器学习的一般原理和处理求方法,能使用机器学习理论解决数据挖掘相关的问题。。教学重教学重点:点、难占八、、Python数据分析与可视化基础认识数据数据预处理回归