
python线性回归实验——【机器学习与算法分析】.pdf

文库****品店


1/10

2/10

3/10

4/10

5/10

6/10
7/10
8/10
9/10

10/10
在线预览结束,喜欢就下载吧,查找使用更方便
相关资料

python线性回归实验——【机器学习与算法分析】.pdf
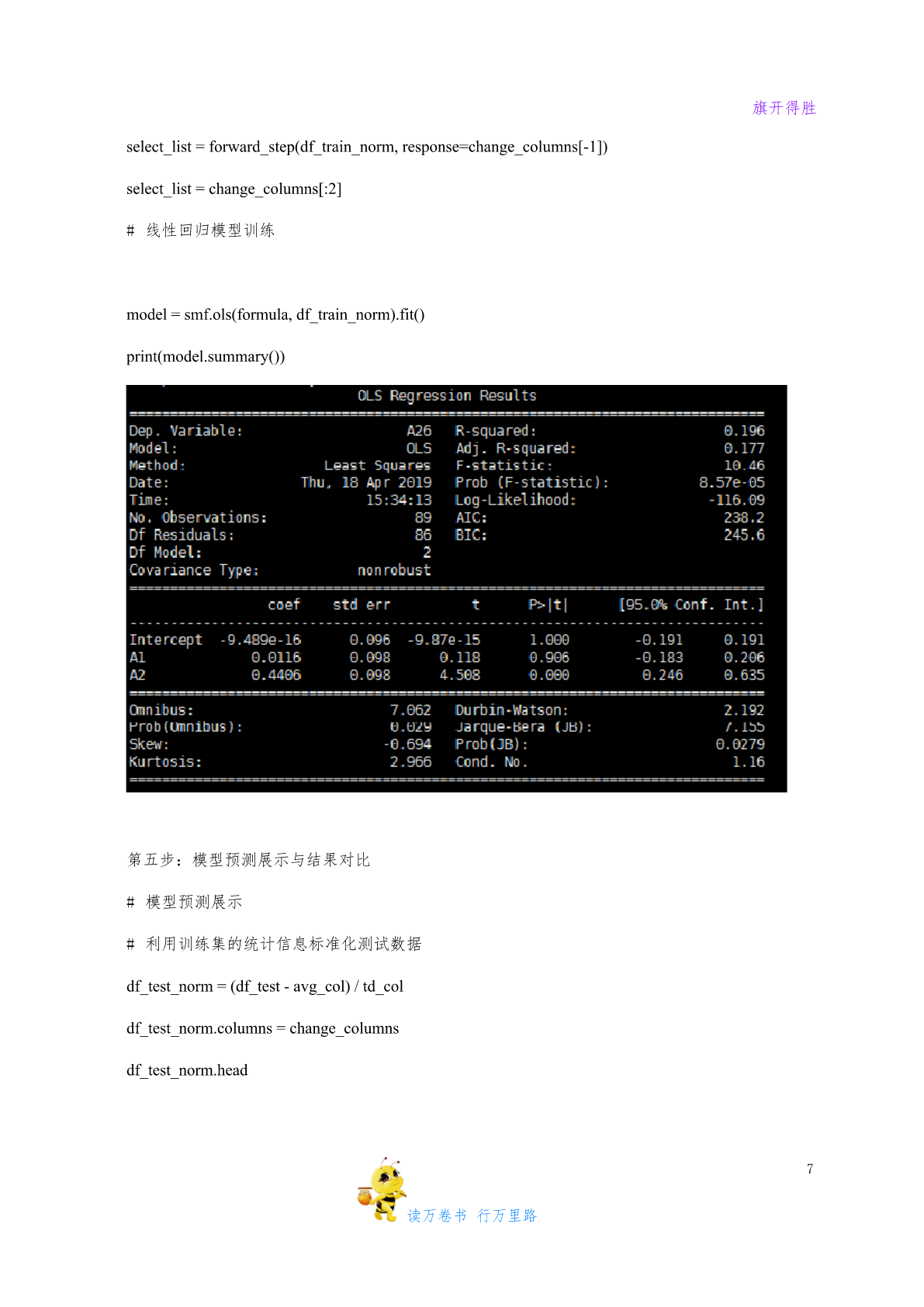
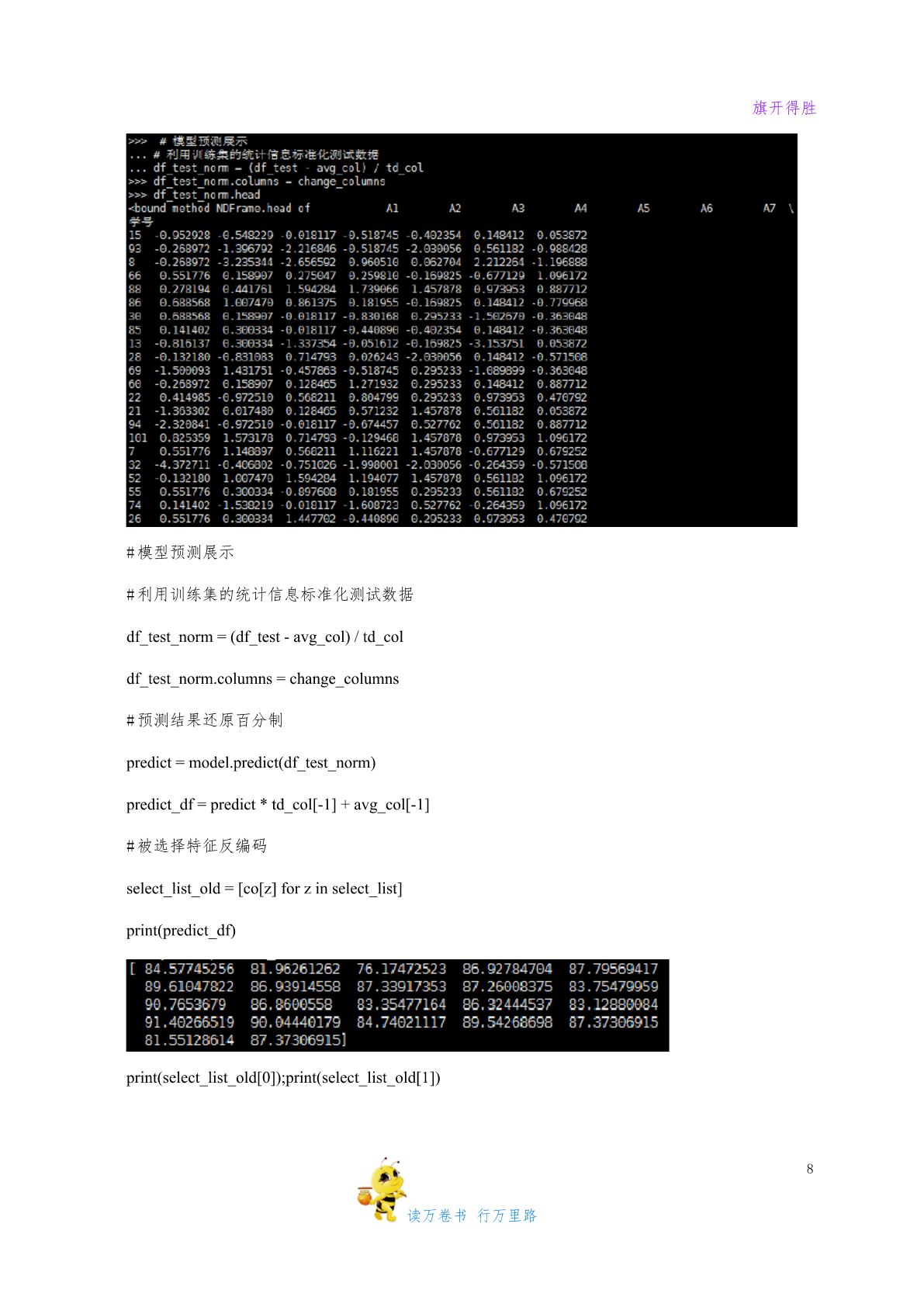
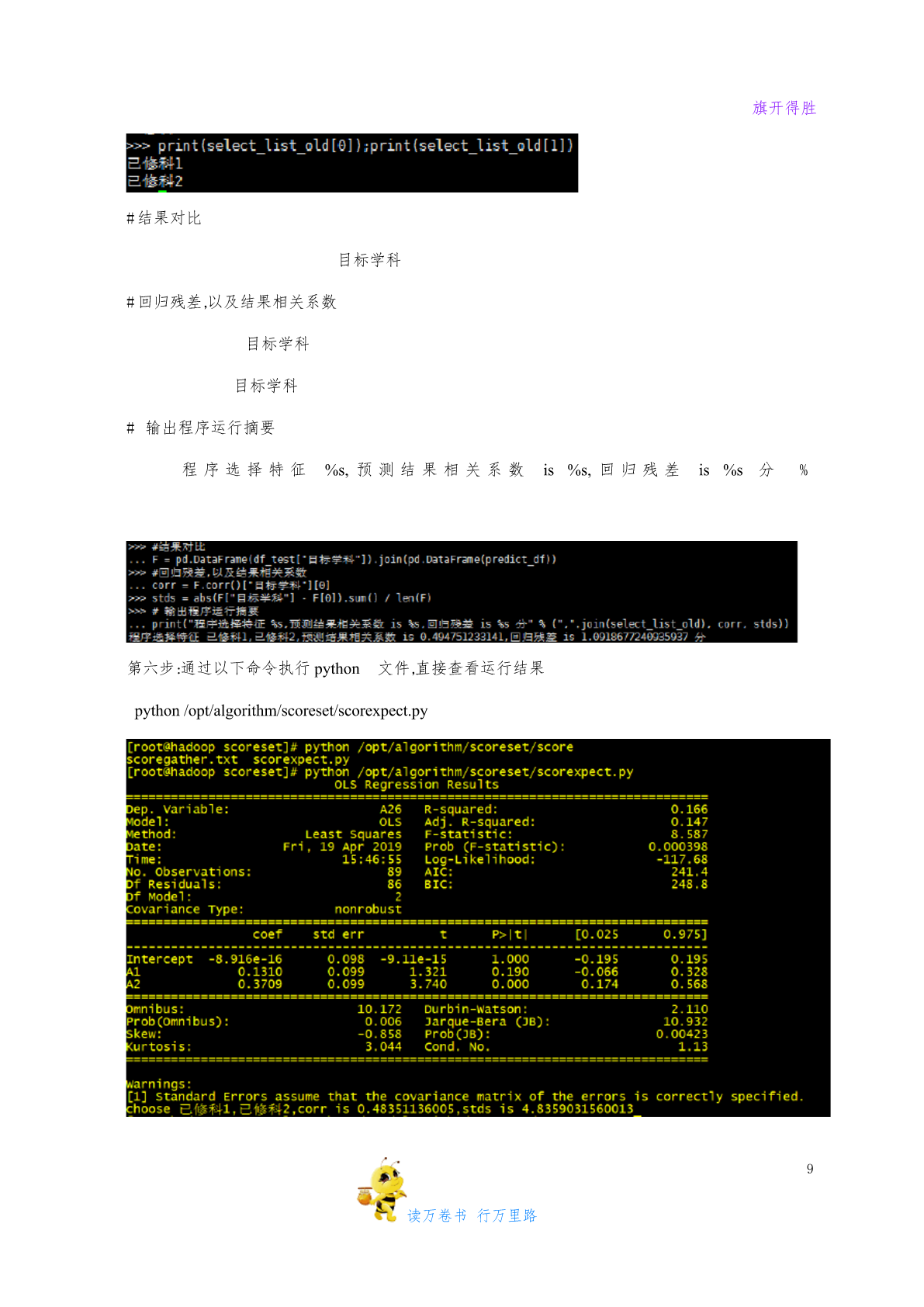
旗开得胜实验算法python线性回归实验【实验名称】Python线性回归实验【实验要求】掌握Python线性回归模型应用过程,根据模型要求进行数据预处理,建模,评价与应用;【背景描述】线性回归是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,运用十分广泛。其表达形式为y=w'x+e,e为误差服从均值为0的正态分布。【知识准备】了解线性回归模型的使用场景,数据标准。了解Python/Spark数据处理一般方法。了解spark模型调用,训练以及应用方法【实验设备】Win

基于Python的机器学习回归算法.pdf
基于Python的机器学习回归算法近年来,人工智能和机器学习成为了科技领域的焦点。在这个技术浪潮的推动下,Python成为了数据科学家和机器学习专家们的最佳选择。Python的卓越性能、易用性和灵活性使得机器学习算法在数据科学中变得非常有效,并且在各种数据挖掘和预测问题中得到了广泛的应用。在这篇文章中,我们将探讨Python机器学习的一个关键应用——回归算法。什么是回归算法?回归算法是一种机器学习技术,用于预测某个连续值输出(数值型)随着不同的输入变量(特征值)而变化的趋势。例如,您可以使用回归分析来预测

基于机器学习线性回归的正规方程分析.docx
基于机器学习线性回归的正规方程分析基于机器学习线性回归的正规方程分析摘要:线性回归是机器学习中最基本的方法之一,它通过寻找数据集中特征与目标变量之间的线性关系来进行预测和分析。本论文主要介绍了线性回归的基本原理,并详细分析了基于正规方程的线性回归方法。正规方程是一种使用矩阵运算来求解线性回归的方法,具有计算简单、效果稳定等优点。本文首先介绍了线性回归的基本概念和模型,然后详细推导了正规方程的求解过程,并通过实例展示了其应用。实验结果表明,基于正规方程的线性回归方法能够有效地进行预测和分析,具有一定的应用价

Python与机器学习算法的应用.pdf
Python与机器学习算法的应用随着时代的发展和科技的进步,机器学习已经成为了许多行业中应用最为广泛的一种技术。而Python作为一种易于上手、开发快速且功能强大的编程语言,也被越来越多的人应用于机器学习领域。Python与机器学习算法的应用,成为了当前热门话题之一。本文将会从机器学习的基础知识开始,探讨Python在机器学习算法应用中的作用、Python的优势及机器学习算法应用案例分析等方面,以此为读者提供有价值的参考。一、机器学习的基础知识机器学习,是一种通过计算机模拟人脑的学习方式来获取知识并进行预

Python中的机器学习算法.pdf