
全文检索引擎API介绍.pdf

文库****品店


1/6

2/6
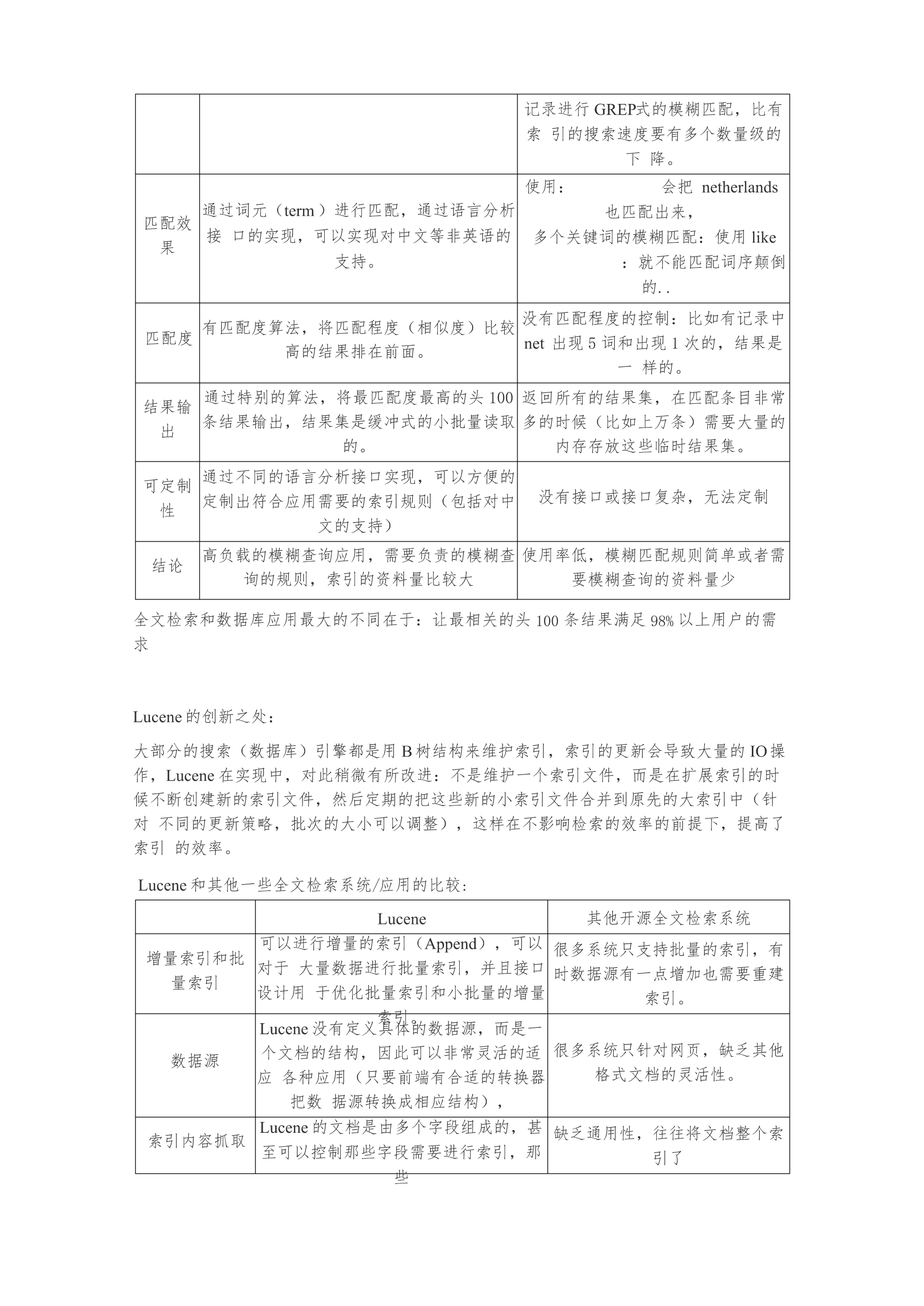
3/6

4/6

5/6

6/6
在线预览结束,喜欢就下载吧,查找使用更方便
相关资料

全文检索引擎API介绍.pdf
Lucene:基于Java的全文检索引擎简介Lucene是一个基于Java的全文索引工具包。1.基于Java的全文索弓I弓I擎Lucene简介:关于作者和Lucene的历史2.全文检索的实现:Luene全文索引和数据库索引的比较3.中文切分词机制简介:基于词库和自动切分词算法的比较4.具体的安装和使用简介:系统结构介绍和演示5.HackingLucene:简化的杳询分析器,删除的实现,定制的排序,应用接口的扩展6.从Lucene我们还可以学到什么基于Java的全文索引/检索引擎一一LuceneLucene

开放源代码的全文检索引擎 Lucene.doc
开放源代码的全文检索引擎Lucene――介绍、系统结构与源码实现分析第一节全文检索系统与Lucene简介一、什么是全文检索与全文检索系统?全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。全文检索的方法主要分为按字检索和按词检索两种。按字检索是指对于文章中的每一个字都建立索引,检索时将词分解为字的组合。对于各种不同
开放源代码的全文检索引擎 Lucene.doc
开放源代码的全文检索引擎Lucene――介绍、系统结构与源码实现分析第一节全文检索系统与Lucene简介一、什么是全文检索与全文检索系统?全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。全文检索的方法主要分为按字检索和按词检索两种。按字检索是指对于文章中的每一个字都建立索引,检索时将词分解为字的组合。对于各种不同
开放源代码的全文检索引擎 Lucene.doc
开放源代码的全文检索引擎Lucene――介绍、系统结构与源码实现分析第一节全文检索系统与Lucene简介一、什么是全文检索与全文检索系统?全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。全文检索的方法主要分为按字检索和按词检索两种。按字检索是指对于文章中的每一个字都建立索引,检索时将词分解为字的组合。对于各种不同

开放源代码的全文检索引擎 Lucene.doc
开放源代码的全文检索引擎Lucene――介绍、系统结构与源码实现分析第一节全文检索系统与Lucene简介一、什么是全文检索与全文检索系统?全文检索是指计算机索引程序通过扫描文章中的每一个词对每一个词建立一个索引指明该词在文章中出现的次数和位置当用户查询时检索程序就根据事先建立的索引进行查找并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。全文检索的方法主要分为按字检索和按词检索两种。按字检索是指对于文章中的每一个字都建立索引检索时将词分