
一种多源异构农业农村大数据分类方法.pdf

是你****松呀


1/10

2/10

3/10

4/10

5/10

6/10

7/10
8/10
9/10
10/10
亲,该文档总共12页,到这已经超出免费预览范围,如果喜欢就直接下载吧~
相关资料

一种多源异构农业农村大数据分类方法.pdf
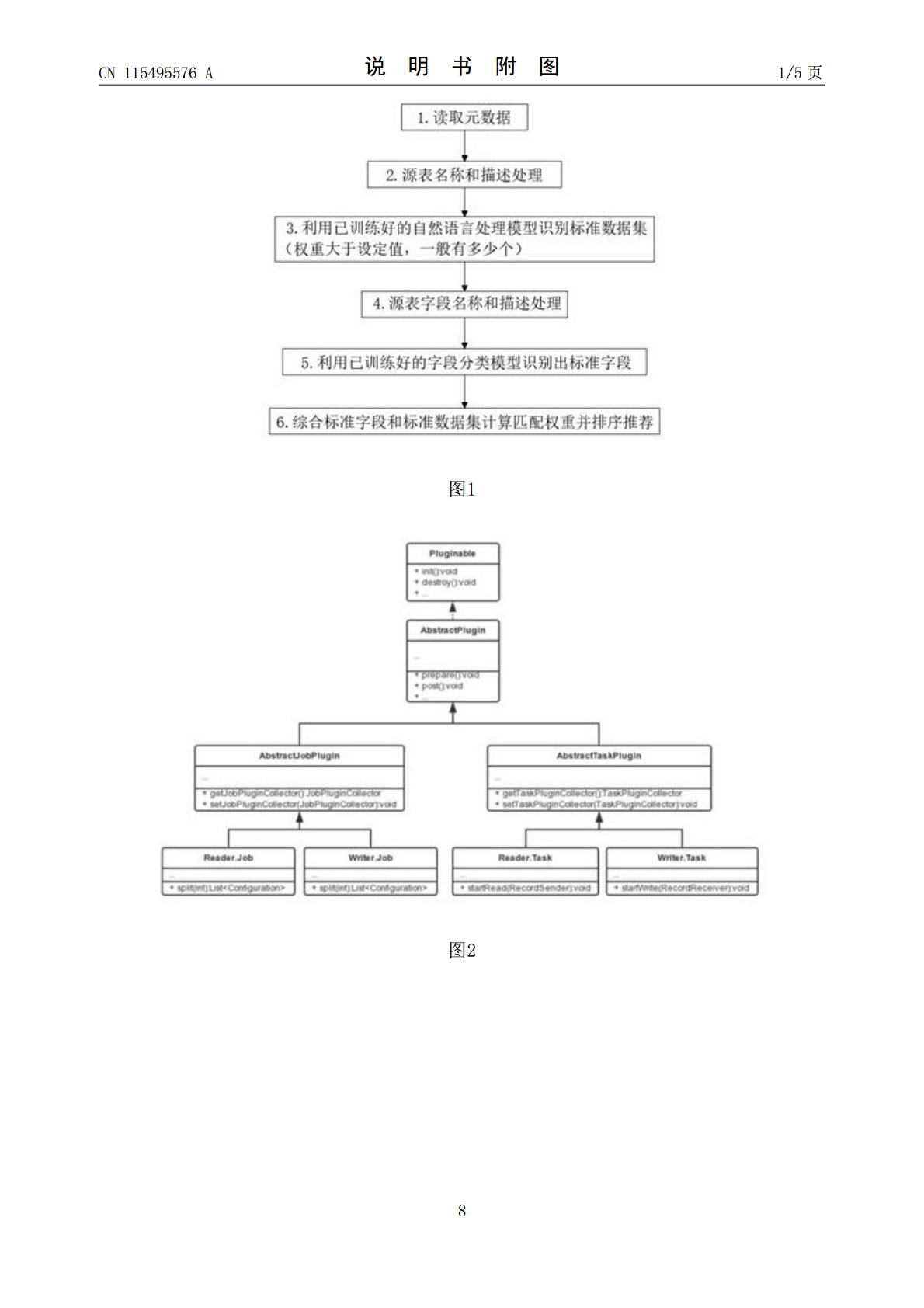
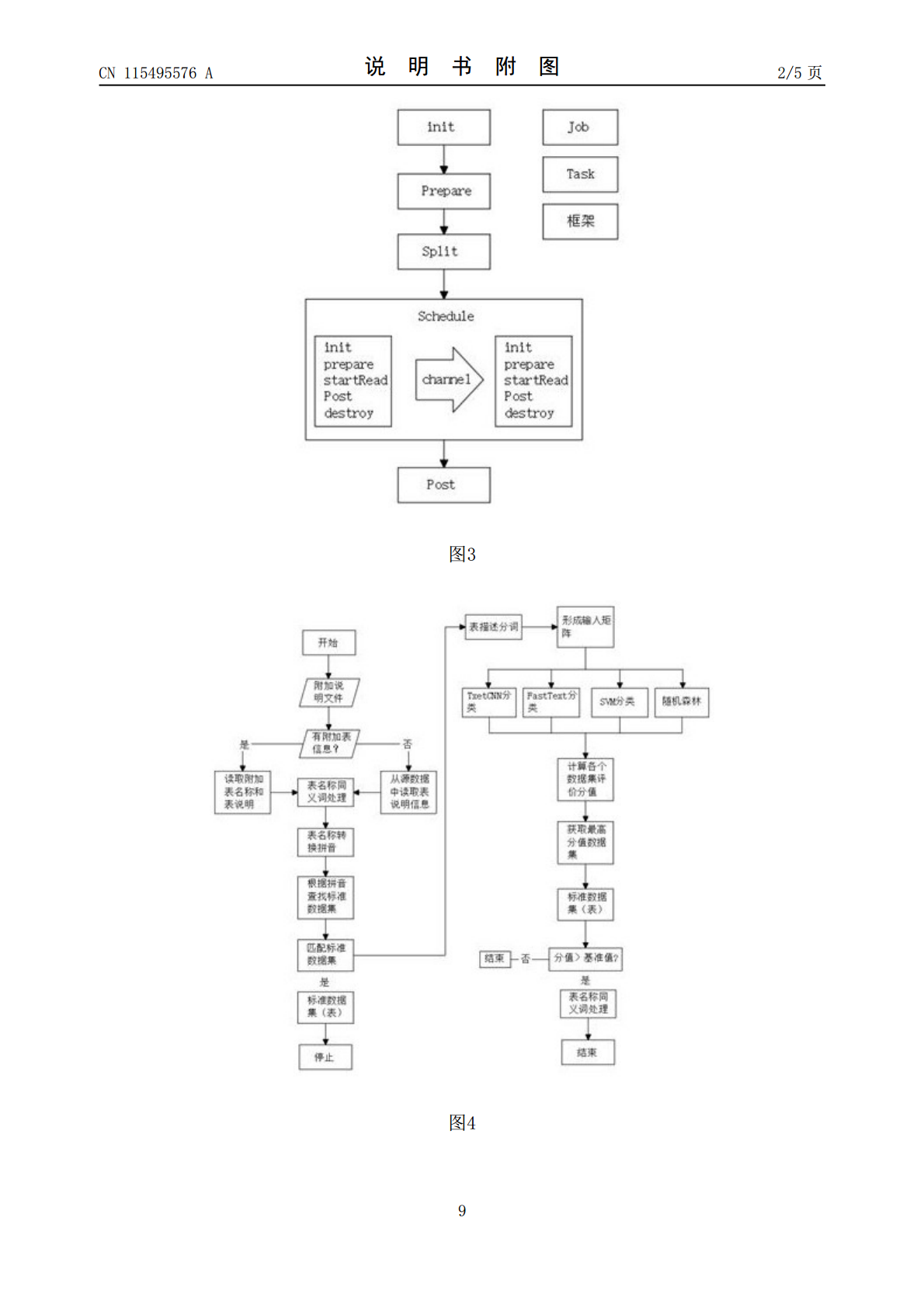
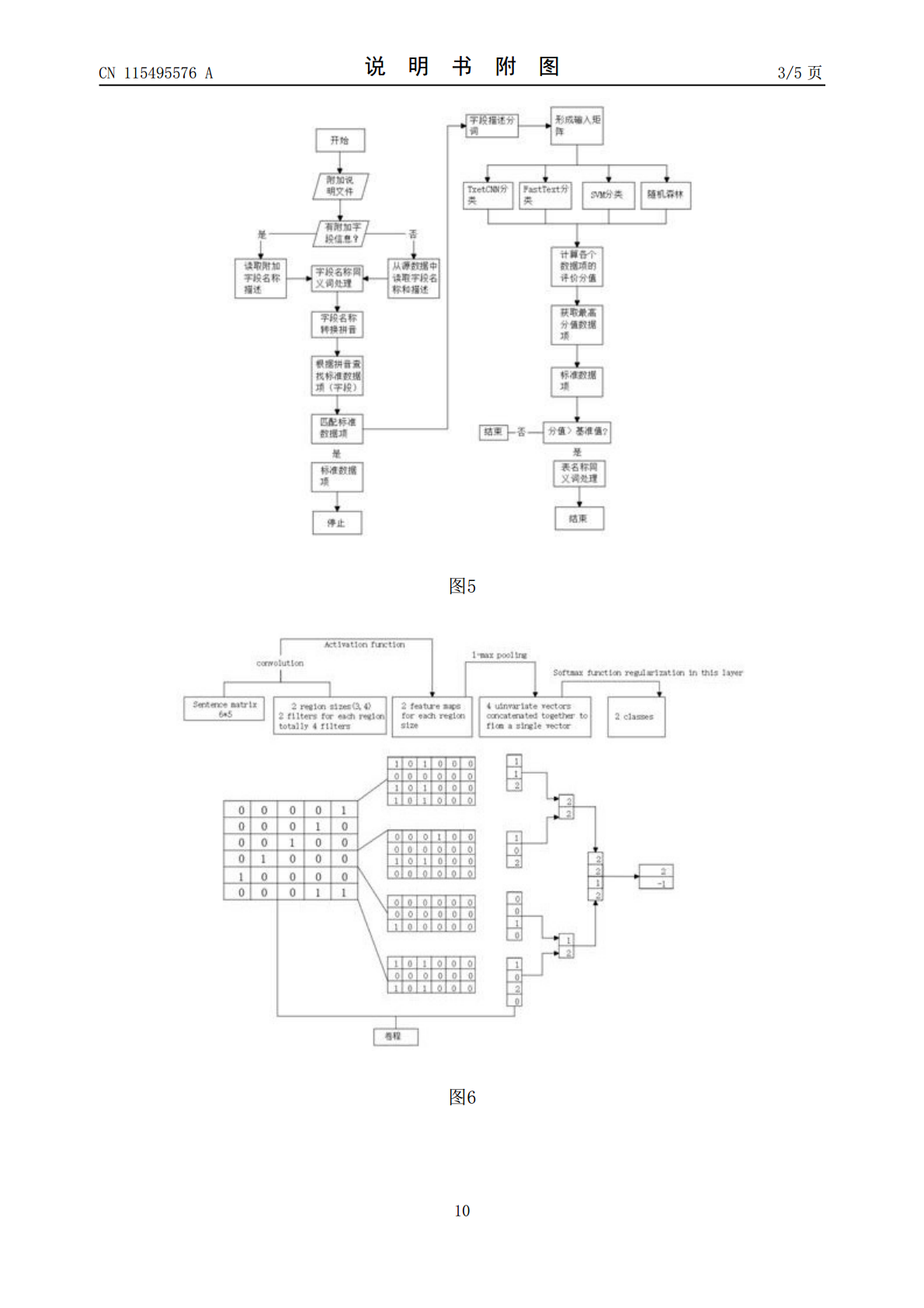
本发明涉及农业农村大数据技术领域,具体揭示了一种多源异构农业农村大数据分类方法,包括如下步骤:S1、首先根据数据源的配置,读取源数据的元数据信息;S2、然后根据源表名称和描述信息,利用已训练好的自然语言处理模型。本发明通过使用自然语言处理分类模型Fasttext、TextCNN、SVM和随机森林完成对表描述和字段描述信息进行分类预测,结合权重计算模型进行分类权重计算,获得精准的标准数据集(表)的推荐和标准数据项(字段)的推荐,达到了自动化效率高的优点,解决了现有的农村大数据读取自动化效率低,往往数据读取都

一种多源异构的数据融合方法及装置.pdf
本申请涉及一种多源异构的数据融合方法及装置,涉及数据处理技术领域,方法包括:获取待融合数据,对待融合数据中各字段赋予不同的权重算子,根据预先设定的数据关联规则和待融合数据中各字段的权重算子对待融合数据进行关联融合,得到待处理数据,最后对待处理数据进行标准化处理。本申请中综合考虑多种因素,对待融合数据中各字段赋予不同的权重算子,如对预期准确度高的字段赋予相对较高的权重算子,对预期准确度低的字段赋予相对较低的权重算子,在进行关联融合时使融合数据对数据的紧密依赖程度更高,从而得到的融合数据更加准确、可靠。

一种多源异构数据字典对齐的方法.pdf
本发明涉及一种多源异构数据字典对齐的方法,属于大数据领域。本发明包括选择源数据库,选择源表,选择作为标准的源字段;选择目标数据库,选择目标表,选择需要对齐的目标字段;选择源表中的数据值;直接选择目数据表中的数据值或者通过算法智能筛选出目标表中的数据值,算法包括但不限于:余弦相似度匹配、编辑距离匹配、经纬度距离匹配、分类编码匹配、时间日期匹配;如果需要将目标表中的数据值扩充到源表中,开启扩充,将该数据值扩充到源表中;匹配成功查看匹配结果。本发明操作简单,匹配的结果也是一目了然,数据字典对齐后也让具体数据值的

多源异构数据融合优化方法.pdf
本发明公开了一种多源异构数据融合优化方法,包括如下步骤:A)对数据实例、类别和属性进行提取和分析,建立词库和短文本库;B)从互联网获取多源异构数据;C)对多源异构数据进行规范化处理,生成短文本;短文本有多个词构成,规范化处理包括分词和去除停用词;D)将短文本作为待匹配短文本,将待匹配短文本与短文本库中存储的短文本进行匹配,得到短文本匹配结果;E)根据短文本匹配结果对数据进行融合,建立大数据内容模型,得到数据融合结果;F)对数据融合结果进行评价,得到评价结果;评价结果包括优、良、中和差。本发明能建立完整性、

多源异构数据多通道数据色彩化转换方法.pdf
多源异构数据多通道数据色彩化转换方法,其转换方法的具体流程如下:一、将多个传感器获取的数字信号输入在n×3的矩阵中形成标准数据;二、将标准数据输入矩阵运算后映射到R、G、B数据,得到n个RGB彩色图像;三、将步骤二获取的n个RGB彩色图像通过矩阵乘法转换为多通道数据融合图像;本发明解决了多个传感器数据表达的复杂性以及RGB表示的实际局限性,在进行多通道数据色彩化转换时实现了最优的准确度。