
人脸识别与语音合成融合系统.pdf

雨巷****轶丽


1/10

2/10

3/10

4/10

5/10

6/10

7/10

8/10
9/10

10/10
在线预览结束,喜欢就下载吧,查找使用更方便
相关资料

人脸识别与语音合成融合系统.pdf
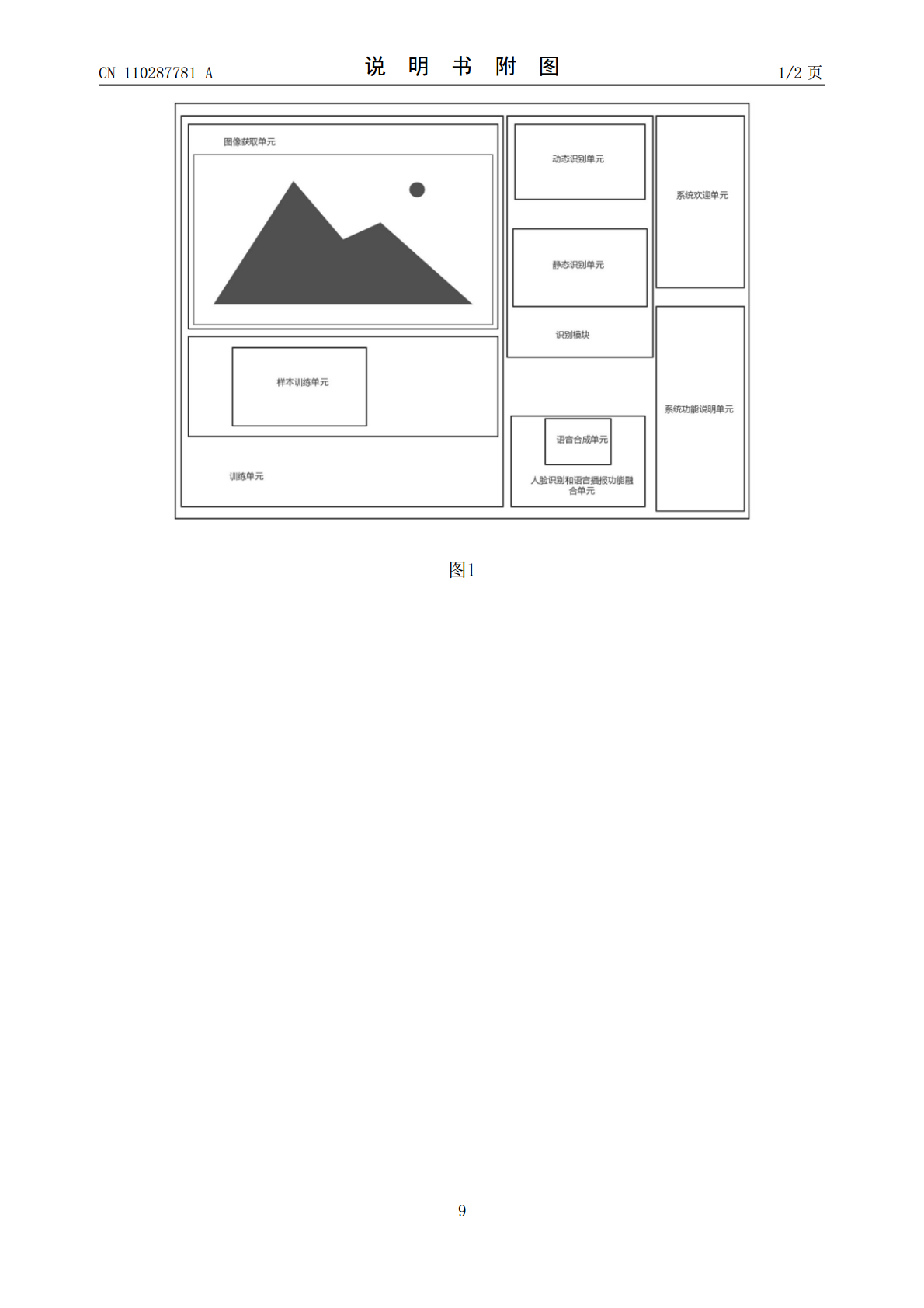
本发明涉及人脸识别与语音合成技术领域,是融合人脸识别与语音合成技术的人脸识别系统,包括:图像获取单元,用于采集人脸识别区域内的图像;样本训练单元,用于对采集到的样本数据并训练模型;动态识别单元,用于动态实时识别人脸;静态识别单元,用于静态识别人脸;语音合成单元,用于语音播报动态识别单元和静态识别单元识别的人脸标识;人脸识别和语音播报功能融合单元,用于实时播报识别出的人脸信息标志。本发明具有速度快,技术融合使得各项操作更加人性化和智能化。本发明直接语音播报识别结果,对于视力有问题的人,比如老人、盲人更加友好

融合人脸表情和语音的双模态情感识别研究的中期报告.docx
融合人脸表情和语音的双模态情感识别研究的中期报告1.研究背景情感识别是计算机视觉和自然语言处理领域的热门研究方向,其涉及到将人类情感表达通过图像识别和声音分析转化为计算机可识别的形式。在实际应用中,情感识别已经被广泛应用于智能客服、情感分析、心理咨询等领域。然而,仅使用单一的情感特征进行识别容易被干扰,且在不同情境下情感表达的方式也存在巨大差异,因此需要结合多种模态来增强识别效果。本文提出了一种融合人脸表情和语音的双模态情感识别方法,旨在提高情感识别准确率和可靠性。2.研究内容本文所提出的双模态情感识别方

语音合成和语音识别.pdf
根据本公开的实现,提出了用于语音合成和语音识别的方案。根据该方案,支持至少一种语言的语音合成(TTS)模型和自动语音识别(ASR)模型被获取。基于目标语言的第一组配对数据来调整该TTS模型和ASR模型,以支持目标语言。然后,基于第一组配对数据和由ASR模型生成的该目标语言的第一组合成配对数据来优化该TTS模型,同时基于第一组配对数据和由TTS模型生成的该目标语言的第二组合成配对数据来优化该ASR模型。以此方式,该方案能够利用较少的训练数据为缺乏训练数据的语言提供具有较高准确性的TTS模型和ASR模型。

基于人脸表情特征与语音特征融合的情感识别研究的任务书.docx
基于人脸表情特征与语音特征融合的情感识别研究的任务书任务书任务名称:基于人脸表情特征与语音特征融合的情感识别研究任务背景:情感识别是一种通过分析人的语音、面部表情和生理反应等多种信号来识别人的情感状态的技术。由于情感识别可以广泛应用于人机交互、情感分析等领域,因此在计算机科学和语音信号处理等相关领域得到了广泛研究。在情感识别中,人脸表情和语音特征是两个重要的信号源。人脸表情可以反映出一个人的情感状态,而语音信号则可以帮助分析一个人的情感状态。然而,对于一个人的情感状态,单独使用人脸表情或语音信号可能会导致

特征融合的VAD方法在语音识别系统中的应用.docx
特征融合的VAD方法在语音识别系统中的应用语音识别是一种将语音信号转化为文本形式的技术,其中关键的环节是语音信号的有效性检测(VoiceActivityDetection,VAD)。随着自然语言处理技术的进步,语音识别的应用场景日益扩大,例如人机交互、智能语音助手、自动翻译等领域。因此,如何提高语音识别系统的准确性和稳定性成为了研究的重点之一。特征融合是一种常见的方法,可用于提高语音识别中的VAD准确性。该方法主要是将多种特征、多个算法、多个模型进行有机结合,以达到最佳效果的目的。在VAD中,一般采用的特