
基于高斯Copula的BPSK信号盲处理结果可信性自适应校验方法.pdf

小代****回来


1/10

2/10

3/10

4/10

5/10

6/10

7/10

8/10
9/10
10/10
在线预览结束,喜欢就下载吧,查找使用更方便
相关资料

基于高斯Copula的BPSK信号盲处理结果可信性自适应校验方法.pdf
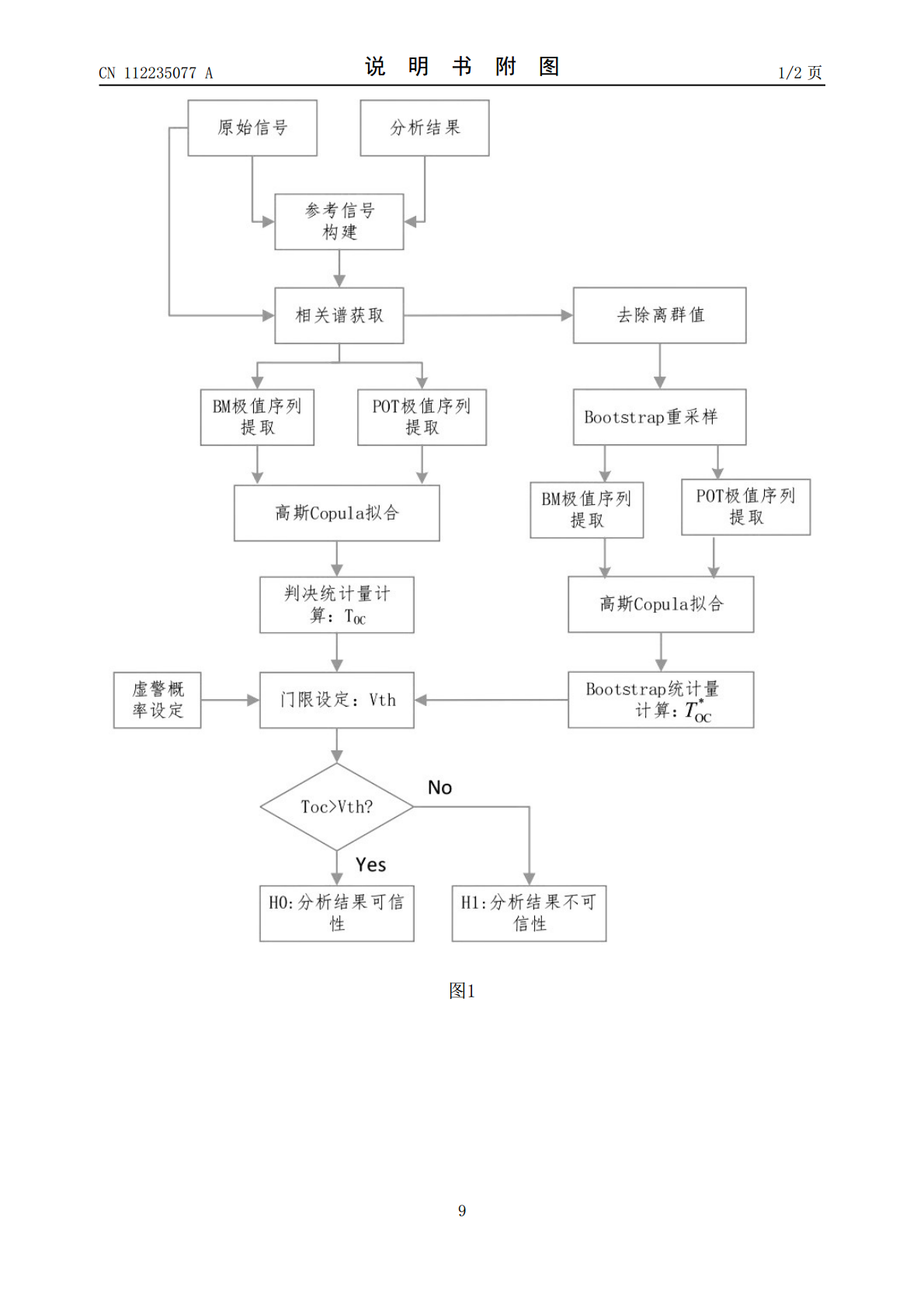
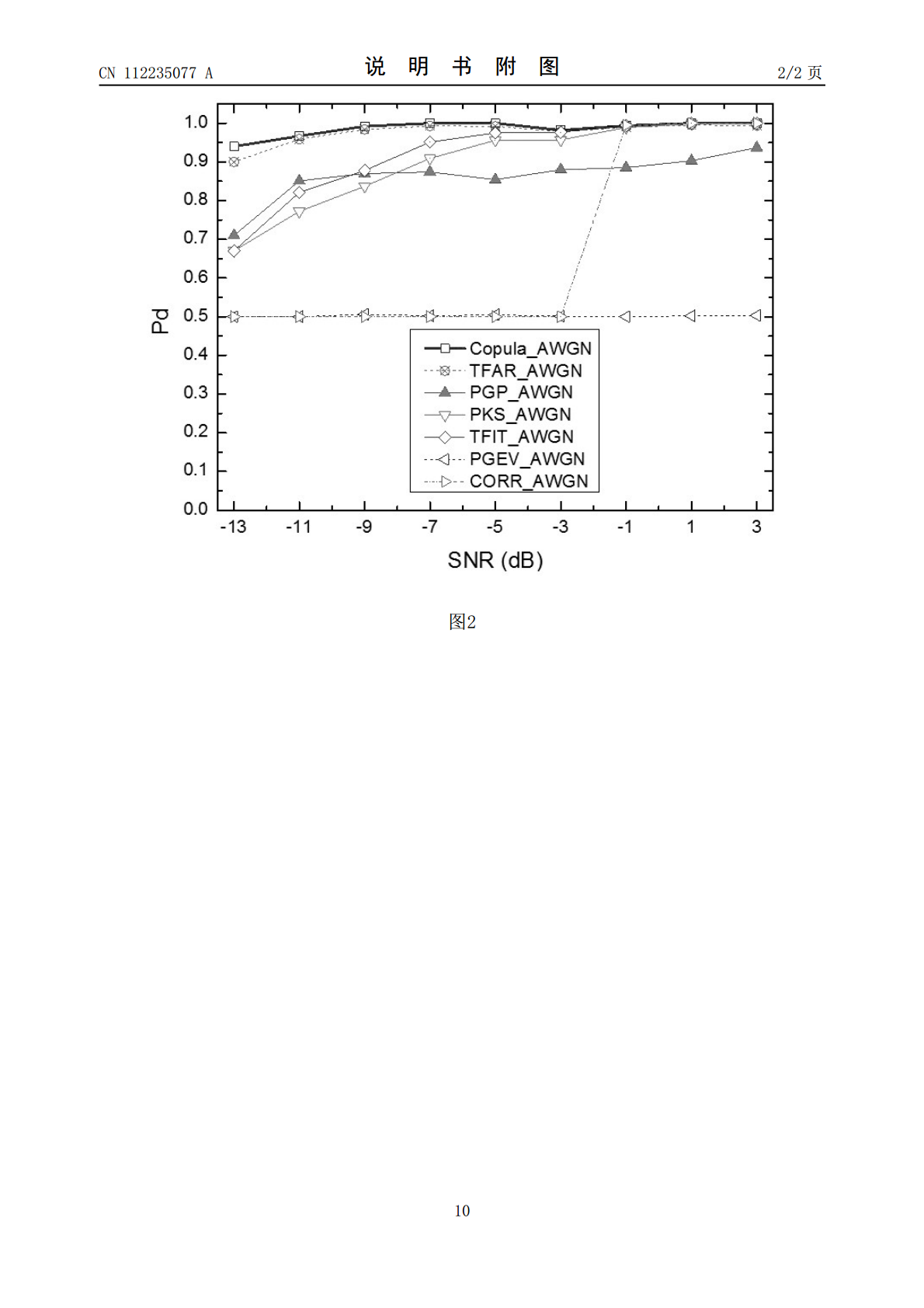
基于高斯Copula的BPSK信号盲处理结果可信性自适应校验方法,首先根据调制识别结果对应的信号模型构造参考信号,计算此参考信号与观测信号的相关谱模值平方;然后分别提取相关谱模值平方序列的分组极值序列及超阈值序列;利用高斯Copula模型对分组极值序列及超阈值序列的联合分布进行拟合,并根据单分类准则,建立校验统计量;利用Bootstrap方法获取统计量在零假设下的概率分布及其数字特征,得到相应的判决门限;若校验统计量大于判决门限,则判定此次BPSK信号盲处理结果为可信,反之,不然。计算机仿真结果表明,该方

基于BM模型的BPSK信号盲处理结果可信性评估方法.pdf
针对BPSK信号盲处理结果可信性评估问题,本发明提出了一种基于BM(blockmaximum,分组极值)模型的可信性评估方法。本方法提取了观测信号与参考信号乘积的相位谱,将其模值平方进行分组并提取每个分组的极大值,构成分组极大值序列;通过检验分组极大值序列是否满足广义极值分布(形状参数为0时)实现对BPSK信号盲处理结果可信性的评估。仿真结果表明:本方法能在无信号参数和噪声功率的情况下,对BPSK信号盲分析结果的正确性和准确性进行评估。

基于POT模型的BPSK信号盲处理结果可信性评估方法.pdf
针对BPSK信号盲处理结果可信性评估问题,本发明提出了一种基于POT(peakoverthreshold,超阈值)模型的可信性评估方法。本方法根据BPSK信号的盲处理结果,构建参考信号,并提取观测信号与参考信号乘积的相位谱,将其模值平方的超阈值序列作为检验统计量。而后,利用KS检验判决统计量是否符合GP分布,以此实现对BPSK信号盲处理结果可信性的评估。仿真结果表明:本方法能在无信号参数和噪声功率的情况下,对BPSK信号盲分析结果的正确性和准确性进行评估。

基于Bootstrap的BPSK信号盲处理结果可信性检验方法.pdf
本发明针对雷达及认知无线电中常用的BPSK信号,提出一种基于Bootstrap的BPSK信号盲处理结果可信性检验方法。该方法首先进行调制方式识别,并根据识别结果对应的模型,进行参数估计及信号重构,分别得到参考信号及重构信号;而后对观测信号进行Bootstrap样本提取,得到观测信号的B个Bootstrap样本集;再将参考信号与观测信号B个Bootstrap样本集分别作N点及N/2点相关累加并取模,得到B个样本值,进而提取两个随机样本集均值比特征;最后在给定的显著水平下,得到判决门限,后通过比较统计量与门限

LFM/BPSK混合调制信号盲处理结果的校验方法.pdf
本发明针对线性调频/二相编码(LFM/BPSK)混合调制信号的盲处理结果,提出了一种通过广义极值(GEV)分布拟合检验的校验方法。首先根据调制识别结果对应的信号模型构造参考信号,计算此参考信号与观测信号的平方相关谱,适当分段后取每个分段的最大值构成分组极值序列,而后利用KS方法对分组极值序列作GEV分布拟合检验,对单次LFM/BPSK信号盲处理的结果作出统计判决。计算机仿真结果表明,该方法可以在缺乏信号及噪声方差信息条件下对LFM/BPSK信号盲处理结果的可信性进行有效检验。