
声纹识别方法和声纹识别系统.pdf

书生****文章


1/10

2/10

3/10

4/10

5/10

6/10

7/10

8/10

9/10
10/10
亲,该文档总共13页,到这已经超出免费预览范围,如果喜欢就直接下载吧~
相关资料

声纹识别方法和声纹识别系统.pdf
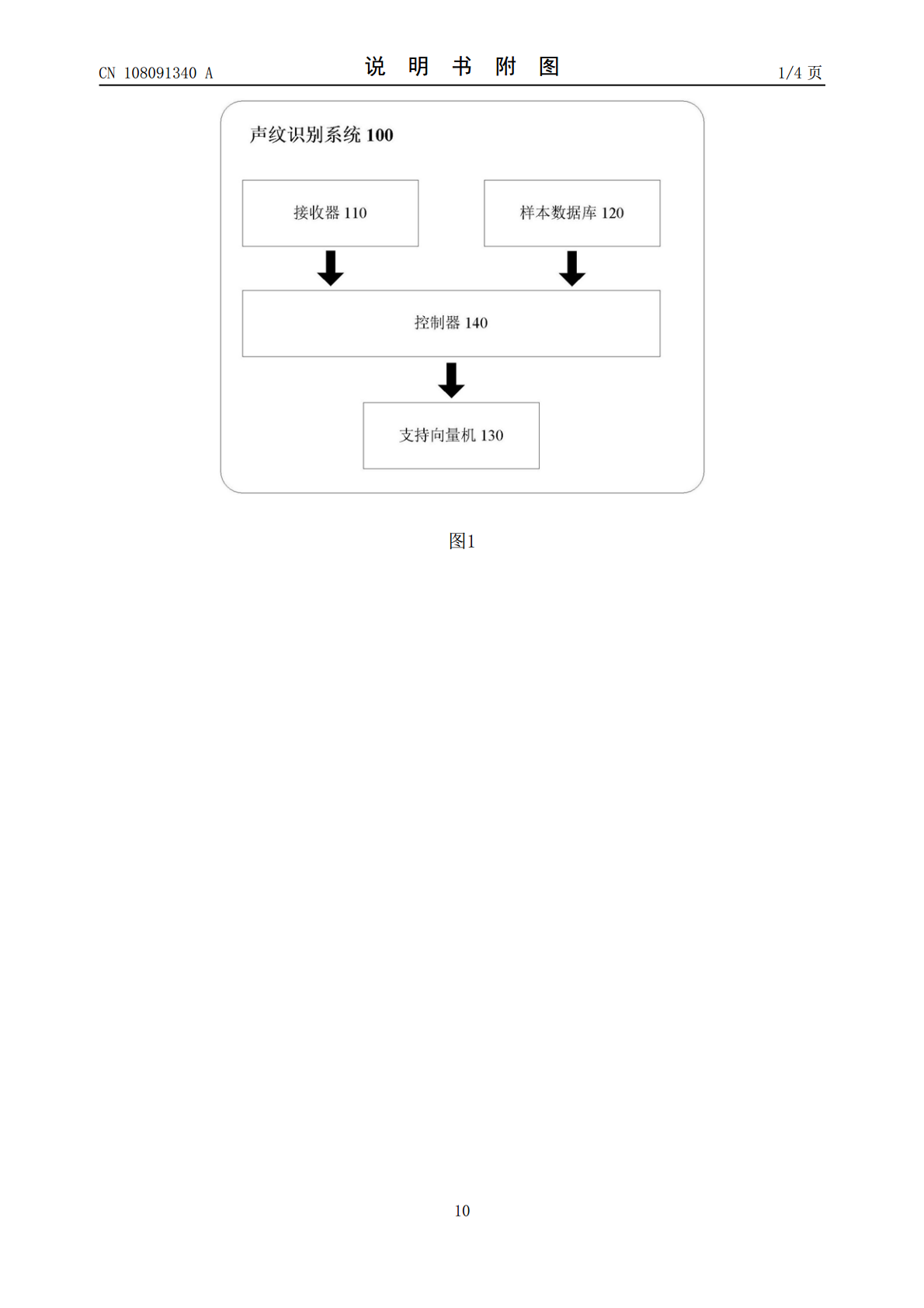
本发明提供了一种声纹识别方法和系统,所述方法包括:接收待测试音频并将其分割为第一和第二部分;选择一个样本音频并将其分割为第一和第二部分;通过使用梅尔倒谱系数的提取方法,提取针对待测试音频和样本音频的特征矩阵;通过将待测试音频的第一部分的特征矩阵作为第一类样本,并将所选样本音频的特征矩阵作为第二类样本,执行支持向量机训练,并计算待测试音频的第二部分与第二类样本的匹配程度;以类似方式针对样本音频的第一部分、待测试音频的第一部分和样本音频的第二部分,分别计算其与对应作为第二类样本的待测试音频、所选样本音频和待测

声纹模型训练和声纹识别方法、装置、设备及介质.pdf
本发明公开了一种声纹模型的训练和声纹识别方法、装置、设备及介质。通过原始声纹模型,确定目标家庭样本集中语音样本中包含的每个语音帧对应的第一声纹向量,将每个第一声纹向量加权后的向量和确定为该语音样本的声纹特征向量,根据该声纹特征向量以及已注册的声纹特征向量,确定第二标识信息,根据第一标识信息和第二标识信息,对原始声纹模型进行训练,从而实现只需根据目标家庭样本集中的语音样本,即可训练出目标家庭对应的声纹模型,节省训练得到声纹模型的时间,由于该声纹模型只需对目标家庭中家庭成员的声纹特征向量进行识别,因此该声纹模

端到端的声纹识别方法和声纹识别装置.pdf
公开了一种端到端的声纹识别方法和声纹识别装置。所述声纹识别方法包括:基于接收的输入语音,使用端到端深度学习网络的说话人语音提取模块执行说话人语音提取任务,以提取目标说话人的语音特征;基于目标说话人的语音特征,使用端到端深度学习网络的说话人识别模块执行说话人识别任务,以在接收的输入语音中识别目标说话人。

一种机顶盒的声纹识别系统及声纹识别方法.pdf
本发明提供一种机顶盒的声纹识别系统及声纹识别方法,其中,系统包括声纹输入单元、特征提取单元、声纹比较单元、数据存储单元、微控制器处理单元;所述特征提取单元用于提取语音信号的特征参数,并输出特征提取后的声纹模拟信号;所述声纹比较单元用于将特征提取后的声纹模拟信号与参照声纹模拟信号进行比较运算后输出数字信号;所述微控制器处理单元用于根据所述数字信号控制所述机顶盒开启或不开启,使得用户仅需向机顶盒的麦克风说出与用户登入账号对应的语音信号即可开启机顶盒,具有操作便捷,用户体验度好的优点,在家庭中使用所述机顶盒时,

一种声纹处理器和声纹验证执行方法.pdf
本发明涉及一种声纹处理器和声纹验证执行方法,声纹处理器包括配置管理器、可重构音频处理引擎和主控制器,所述主控制器通过配置总线和配置管理器双向互连,所述主控制器通过外部接口和可重构音频处理引擎双向互连,所述配置管理器和可重构音频处理引擎双向互连;所述可重构音频处理引擎具有向量点乘、张量乘积、卷积、快速傅立叶变换功能。本发明的声纹处理器面积小、功耗低,但功能齐全,能动态配置不同算法的布局布线,因此PE处理单元利用率高。