
一种基于深度波束形成的多通道语音增强方法.pdf

一只****呀盟


1/10

2/10

3/10

4/10

5/10

6/10

7/10

8/10

9/10
10/10
在线预览结束,喜欢就下载吧,查找使用更方便
相关资料

一种基于深度波束形成的多通道语音增强方法.pdf
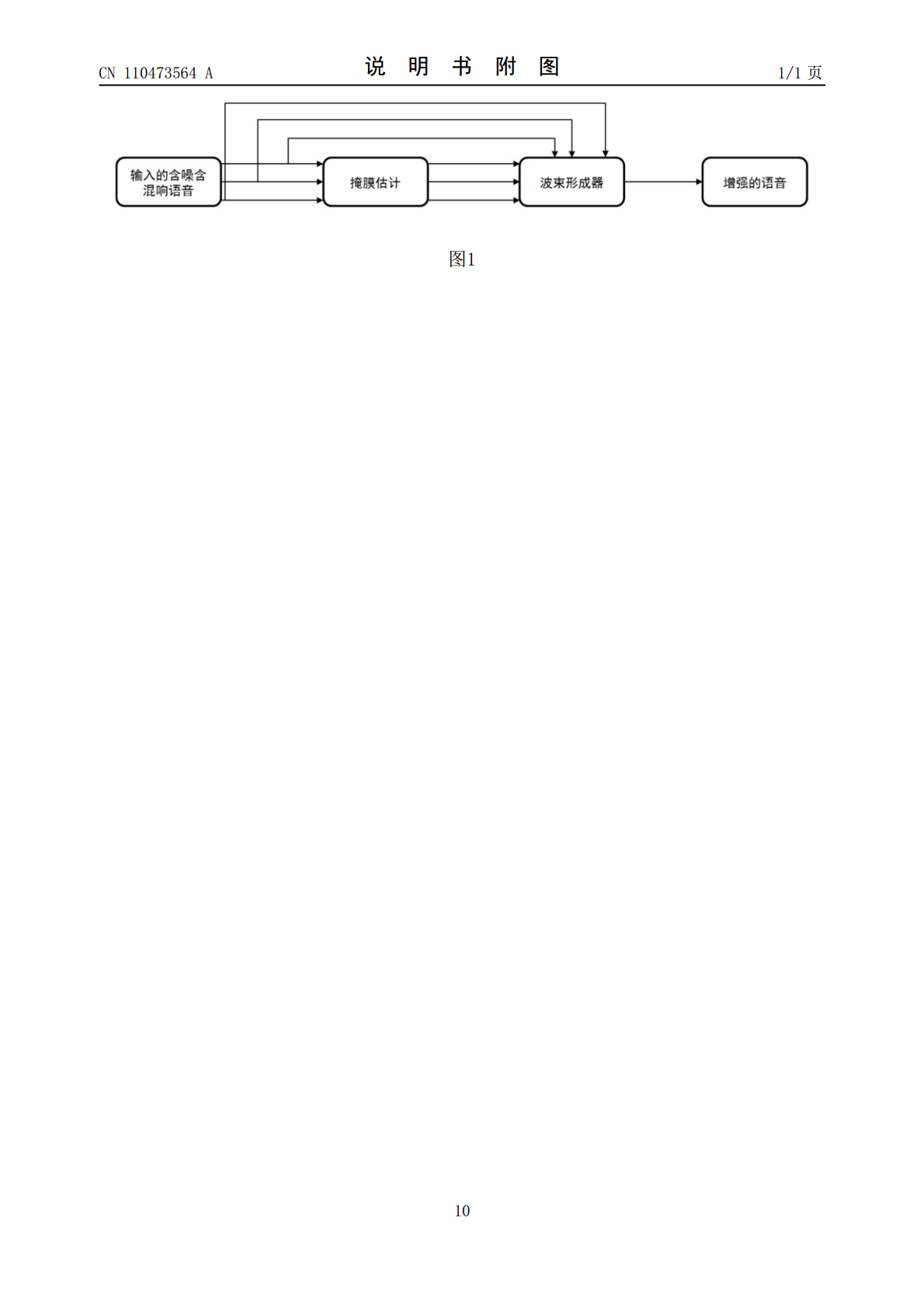
本发明涉及一种基于深度波束形成的多通道语音增强方法,首先采集多个麦克风接收到的语音信号;然后提取要处理语音的对数梅尔滤波器组特征;将每个通道的特征送入双向长短时记忆网络(BLSTM,BidirectionalLong‑ShortTimeMemory)得到增强后的理想比率掩膜(IRM,IdealRatioMask);将得到的掩膜用于计算GEV的语音和噪声协方差矩阵,进而得到增强后的语音。相比基于MVDR波束形成器的多通道语音增强方法,本方法得到的增强语音效果更好。

基于波束形成与多参考源噪声对消的语音增强算法.docx
基于波束形成与多参考源噪声对消的语音增强算法一、引言在日常生活中,语音通信是人与人之间基本的交流方式之一。但是在嘈杂的环境中进行语音通信时,噪声会对语音质量产生很大的影响,这时就需要进行语音增强处理来提高语音的可听性和清晰度。波束形成与多参考源噪声对消是比较常见的语音增强算法,本文将介绍基于该算法的语音增强处理方法。二、波束形成与多参考源噪声对消算法波束形成是一种基于阵列信号处理技术的方法,它是通过选择性增强某一方向的信号而抑制其他方向的干扰信号。在语音通信中,采用波束形成可以使得语音信号的质量得到提高。

《2024年基于深度学习的多通道语音增强方法研究》范文.pdf
《基于深度学习的多通道语音增强方法研究》篇一一、引言随着信息技术的迅猛发展,语音通信技术越来越成为我们日常生活中不可或缺的一部分。然而,在实际的语音通信过程中,由于各种环境噪声的干扰,语音信号的质量常常受到影响。因此,如何有效地进行语音增强,提高语音信号的信噪比(SNR),成为了语音处理领域的重要研究方向。近年来,基于深度学习的多通道语音增强方法因其出色的性能和适应性,受到了广泛关注。本文将对这一方法进行深入研究,以期为相关领域的研究提供有价值的参考。二、深度学习与语音增强深度学习是一种基于神经网络的机器

基于噪声抵消与波束形成的小阵语音增强.docx
基于噪声抵消与波束形成的小阵语音增强基于噪声抵消与波束形成的小阵语音增强摘要:随着通信技术的进步,语音通信成为人们日常生活中重要的一部分。然而,由于环境噪声的干扰,语音信号的质量经常受到影响。为了提高语音通信质量,本文提出了基于噪声抵消与波束形成的小阵语音增强方法。首先,通过使用传感器阵列采集环境中的原始语音信号和噪声信号,可以通过简单但有效的噪声抵消算法减少背景噪声的影响。其次,利用波束形成技术可以提取出感兴趣的语音源。最后,通过将波束形成和噪声抵消相结合,可以显著地提高语音信号的质量。实验结果表明,本

多通道语音增强方法简介.docx
多通道语音增强方法简介【摘要】由于多麦克风越来越多地部署到同一个设备上基于双麦克风和麦克风阵列的多通道语音增强研究有了较大的应用价值。介绍了自适应噪声对消法、FDM等双通道语音增强方法和波束形成、独立分量分析等麦克风阵列语音增强方法对各个方法的原理、发展和优缺点进行了详细分析和总结对多通道语音增强深入研究有一定帮助。【关键词】语音增强;双通道;麦克风阵列;波束形成1.引言语音是人们通讯交流的主要方式之一。我们生活的环境中不可避免地存在着噪声混入