
一种基于紧密卷积的神经网络模型的声音场景识别方法.pdf

光誉****君哥


1/10

2/10

3/10

4/10

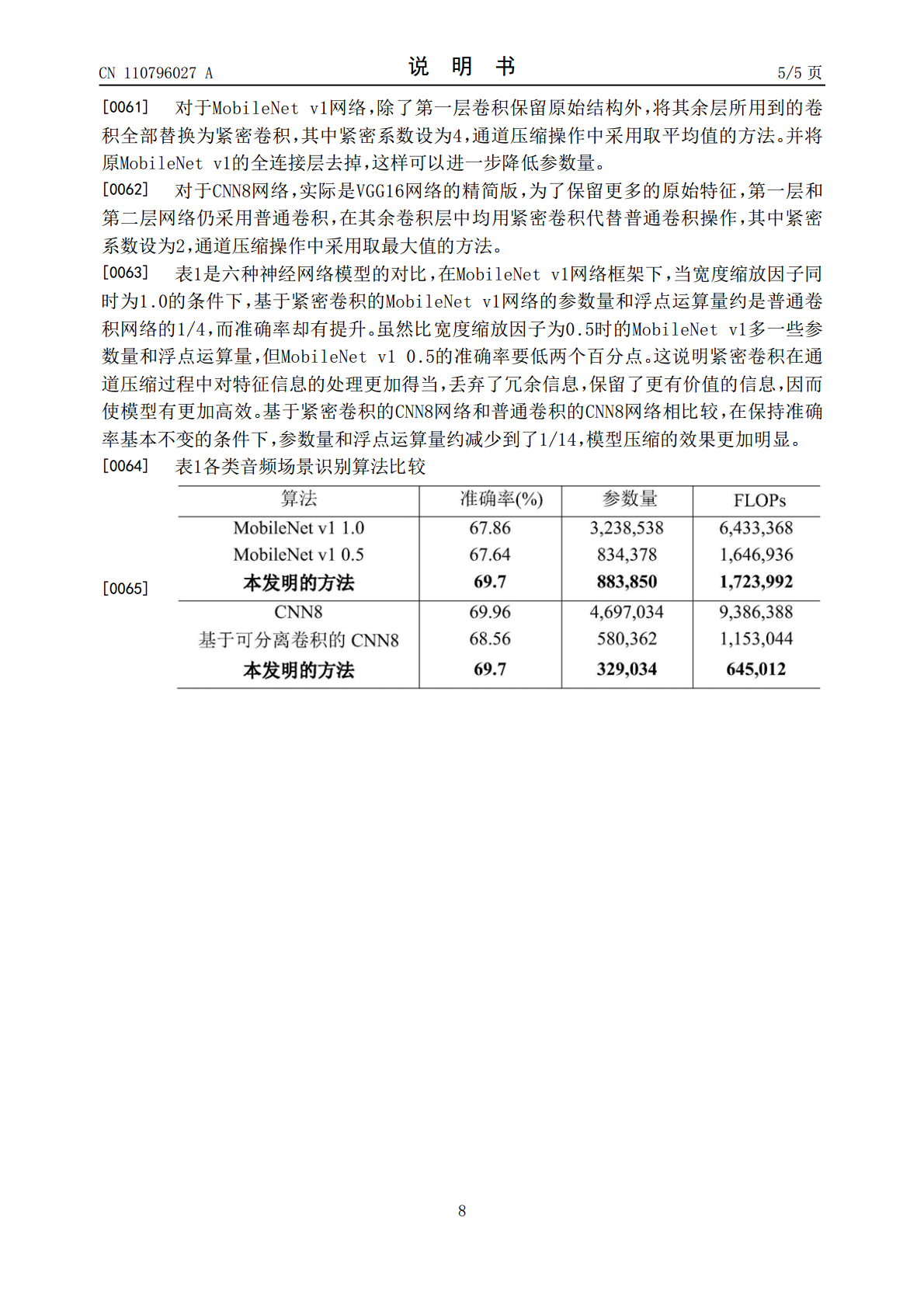
5/10

6/10

7/10
8/10
9/10

10/10
亲,该文档总共11页,到这已经超出免费预览范围,如果喜欢就直接下载吧~
相关资料

一种基于紧密卷积的神经网络模型的声音场景识别方法.pdf
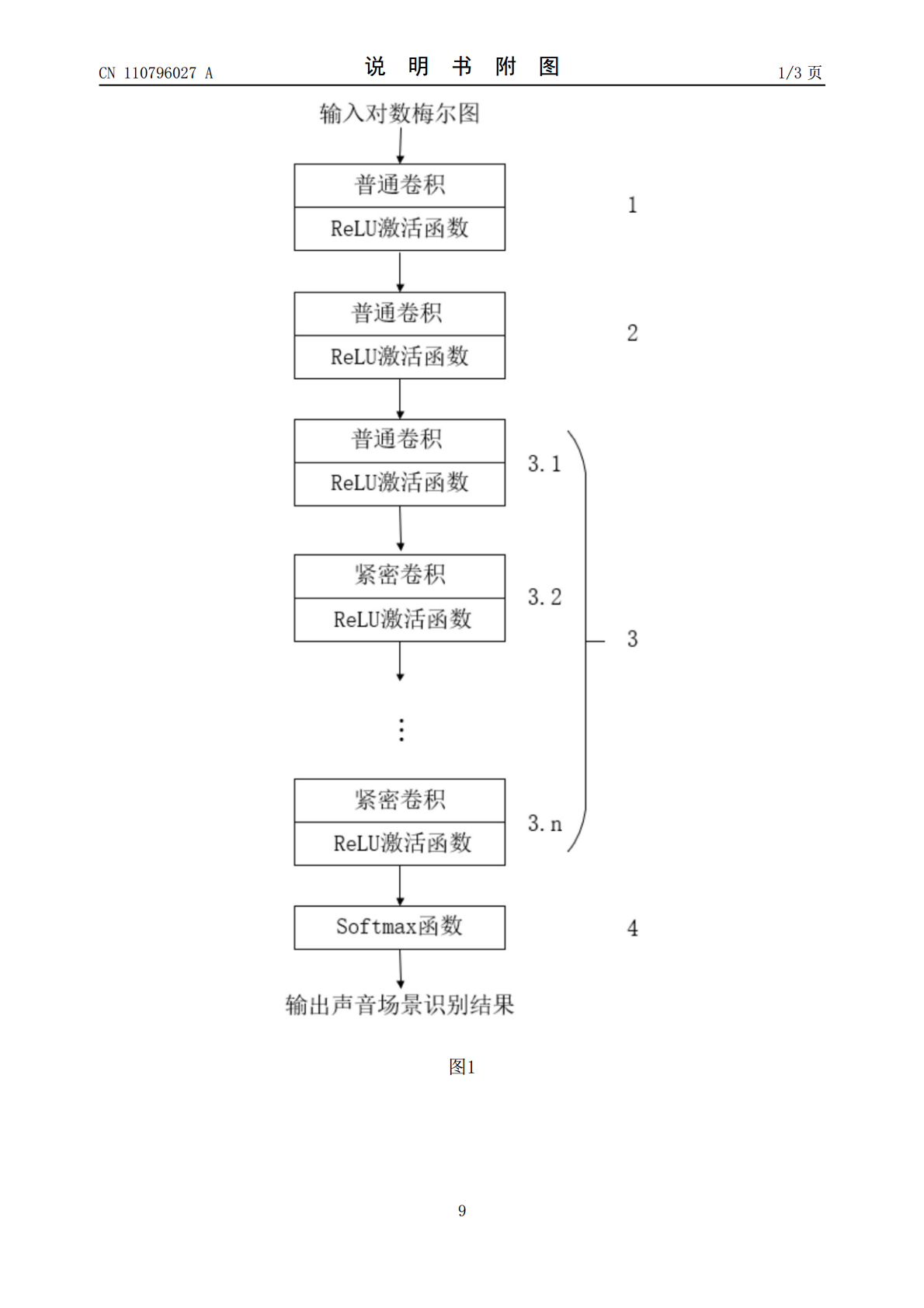
一种基于紧密卷积的神经网络模型的声音场景识别方法:建立用于声音场景分类的紧密卷积的神经网络模型;将包含有不同场景类别的音频文件和对应的场景类别的训练集输入用于声音场景分类的紧密卷积的神经网络模型,对用于声音场景分类的紧密卷积的神经网络模型进行训练;读取音频文件并进行预处理,得到音频信号片段;从所述的音频信号片段中提取对数梅尔图;将所述的对数梅尔图输入到训练后的用于声音场景分类的紧密卷积的神经网络模型中,得到最终的声音场景类别。本发明既保证了有效特征得以充分的利用而使准确率不变,又精简了网络模型而减少内存消

一种基于卷积神经网络模型的目标检测识别方法.pdf
本发明提供了一种基于卷积神经网络模型的目标检测识别方法,首先构建Dense‑Spp‑Gaussion网络模型,以密集连接DenseNet网络为骨干网络,引入空间金字塔池化结构和多尺度检测,并采用Gaussian模型对网络输出进行建模,可以得到每个预测框的可靠性,提升检测精度,然后预测值与真实值之间的误差构建损失函数,迭代更新模型参数使得损失函数收敛,最后获得训练好的模型用于目标检测识别。本发明采用4种尺度检测,提高了对小目标的检出率,并用Gaussian模型对位置信息进行建模,得到定位准确度信息,提升了总

基于卷积神经网络的环境声音识别方法及系统.pdf
一种基于卷积神经网络的环境声音识别方法及系统,将从音频中提取得到的梅尔能量谱特征进行混合构建得到样本库,用于对卷积神经网络模型进行训练,最终以训练后的卷积神经网络进行环境声音的识别,本发明在ESC‑10、ESC‑50和UrbanSound8K三个公开声音数据集上取得了最好或者接近最好的结果。

基于卷积神经网络的多模型交通场景识别研究.docx
基于卷积神经网络的多模型交通场景识别研究摘要交通场景识别是计算机视觉的关键性应用之一,基于卷积神经网络的交通场景识别已经在交通领域取得了广泛的应用。多模型融合技术可以进一步提高交通场景的识别性能,同时也是目前研究的热点之一。本文提出了一种基于卷积神经网络的多模型交通场景识别方法,通过使用多种传感器获取的信息,实现了对交通场景的准确识别。实验结果表明,所提出的方法可以有效地提高识别性能,实现了最高准确率达到95%的识别效果。关键词:交通场景识别;卷积神经网络;多模型融合;传感器数据;识别性能引言交通场景识别

基于卷积神经网络与多尺度空间编码的场景识别方法.docx
基于卷积神经网络与多尺度空间编码的场景识别方法基于卷积神经网络与多尺度空间编码的场景识别方法摘要:场景识别是计算机视觉领域的重要任务之一,对于智能机器的发展和应用具有重要意义。卷积神经网络(CNN)是目前最为广泛应用于图像识别任务的深度学习模型,其在图像特征提取和模式分类方面取得了显著成果。然而,传统的CNN仅通过单一尺度的图像特征提取,对于场景识别来说存在一定的局限性。为了解决这一问题,本文提出了一种基于卷积神经网络与多尺度空间编码的场景识别方法。通过引入多个尺度的图像特征编码,利用卷积神经网络进行深层