
一种基于时域卷积编解码网络的语音识别方法.pdf

是你****盟主


1/9

2/9

3/9

4/9

5/9

6/9

7/9

8/9
9/9
在线预览结束,喜欢就下载吧,查找使用更方便
相关资料

一种基于时域卷积编解码网络的语音识别方法.pdf
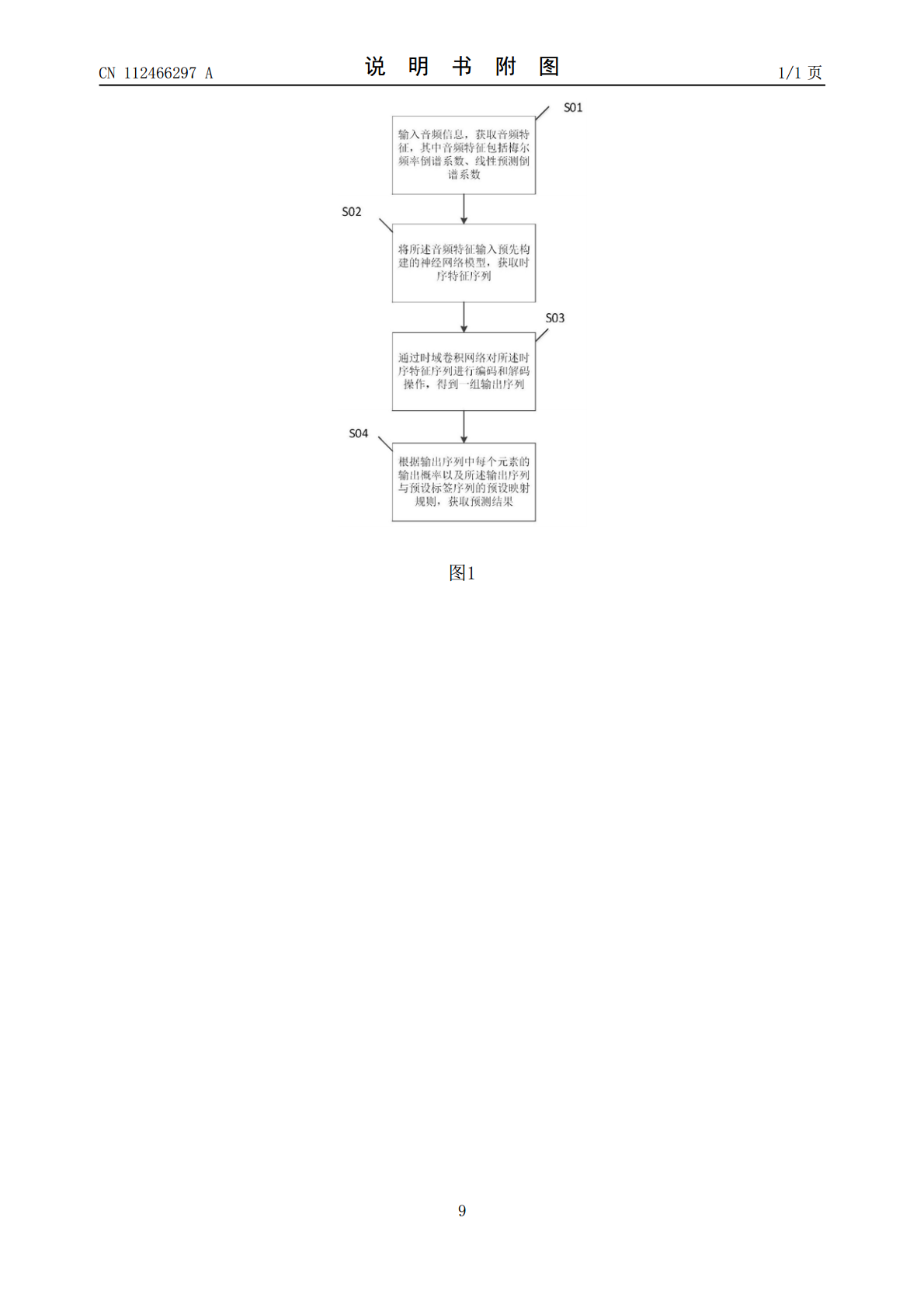
本发明提出一种基于时域卷积编解码网络的语音识别方法,包括:输入音频信息,获取音频特征,其中音频特征包括梅尔频率倒谱系数、线性预测倒谱系数;将所述音频特征输入预先构建的神经网络模型,获取时序特征序列;通过时域卷积网络对所述时序特征序列进行编码和解码操作,得到一组输出序列;根据输出序列中每个元素的输出概率以及所述输出序列与预设标签序列的预设映射规则,获取预测结果;本发明可有效解决语音识别延迟问题。

一种基于卷积神经网络的动载荷时域识别方法.pdf
本发明提出了一种基于卷积神经网络的动载荷时域识别方法。首先通过试验/理论分析得到大量动力学系统的振动响应数据,将振动响应数据分为训练集、验证集、测试集。随后基于卷积神经网络理论搭建动载荷识别的逆向模型,建立系统响应与外载荷之间的内在关系,采用梯度下降算法更新逆向模型参数,进一步提高动载荷的识别精度。而后利用训练集数据对模型进行训练,建立预测载荷与试验室标准载荷的损失函数,采用梯度下降算法对CNN模型的参数进行更新,引入dropout算法提升模型的泛化能力。相较于传统的动载荷识别方法,本发明方法在仅有系统响

一种基于卷积神经网络特征表征的语音情感识别方法.docx
一种基于卷积神经网络特征表征的语音情感识别方法基于卷积神经网络特征表征的语音情感识别方法摘要:语音情感识别作为一种重要的研究领域,对于人机交互、情感研究以及智能系统的发展都具有重要意义。本文提出一种基于卷积神经网络特征表征的语音情感识别方法,通过提取语音信号的时域和频域特征,并结合卷积神经网络进行情感分类。实验结果表明,该方法在语音情感识别任务上取得了良好的性能。关键词:语音情感识别;卷积神经网络;特征表征;时域特征;频域特征1.引言情感是人类交流和表达情绪的重要方式之一,因此语音情感识别一直是一个具有挑

一种基于旁路卷积神经网络的视觉语音识别方法及其应用.pdf
本发明公开了一种基于旁路卷积神经网络的视觉语音识别方法及其应用,该方法包括:1、构建视觉语音识别数据集以及数据的预处理;2、构建基于旁路卷积神经的视觉语音识别网络,将预处理得到的唇读图像序列和像素级嘴唇轮廓图像序列输入到双分支架构的视觉语音识别网络两个分支中,具体两个分支均包括时空3D特征提取模块、2D时空特征提取模块、互相关时序解码模块、分类模块;3、基于旁路卷积神经的视觉语音识别网络的训练。本发明通过经掩码处理的数据,减少除嘴唇外额外的视觉信息对识别所带来的影响,从而能使识别模型摆脱说话者依赖,进而为

动态时域卷积网络驱动的多模态情感识别方法.pdf
本发明公开了动态时域卷积网络驱动的多模态情感识别方法,利用三种模态特征生成查询向量,通过注意力机制增强各模态特征,明确捕捉到各模态特征中与模态间交互作用相关的信息,使模型更容易地建模不同模态之间的交互作用;通过具有动态卷积特性的时域卷积网络来学习查询向量,不仅使查询向量的学习过程更加充分合理,而且通过动态卷积,使查询向量的生成随输入特征动态变化,更贴合目标任务;给出的时域卷积网络通过动态卷积的方式来生成卷积核,使卷积核随输入特征呈现动态变化,与输入特征更适配,有助于更灵活地建模多模态特征之间的交互作用;这