
一种基于时间序列的水质预测方法.pdf

白凡****12


1/9

2/9

3/9

4/9

5/9

6/9

7/9

8/9
9/9
在线预览结束,喜欢就下载吧,查找使用更方便
相关资料

一种基于时间序列的水质预测方法.pdf
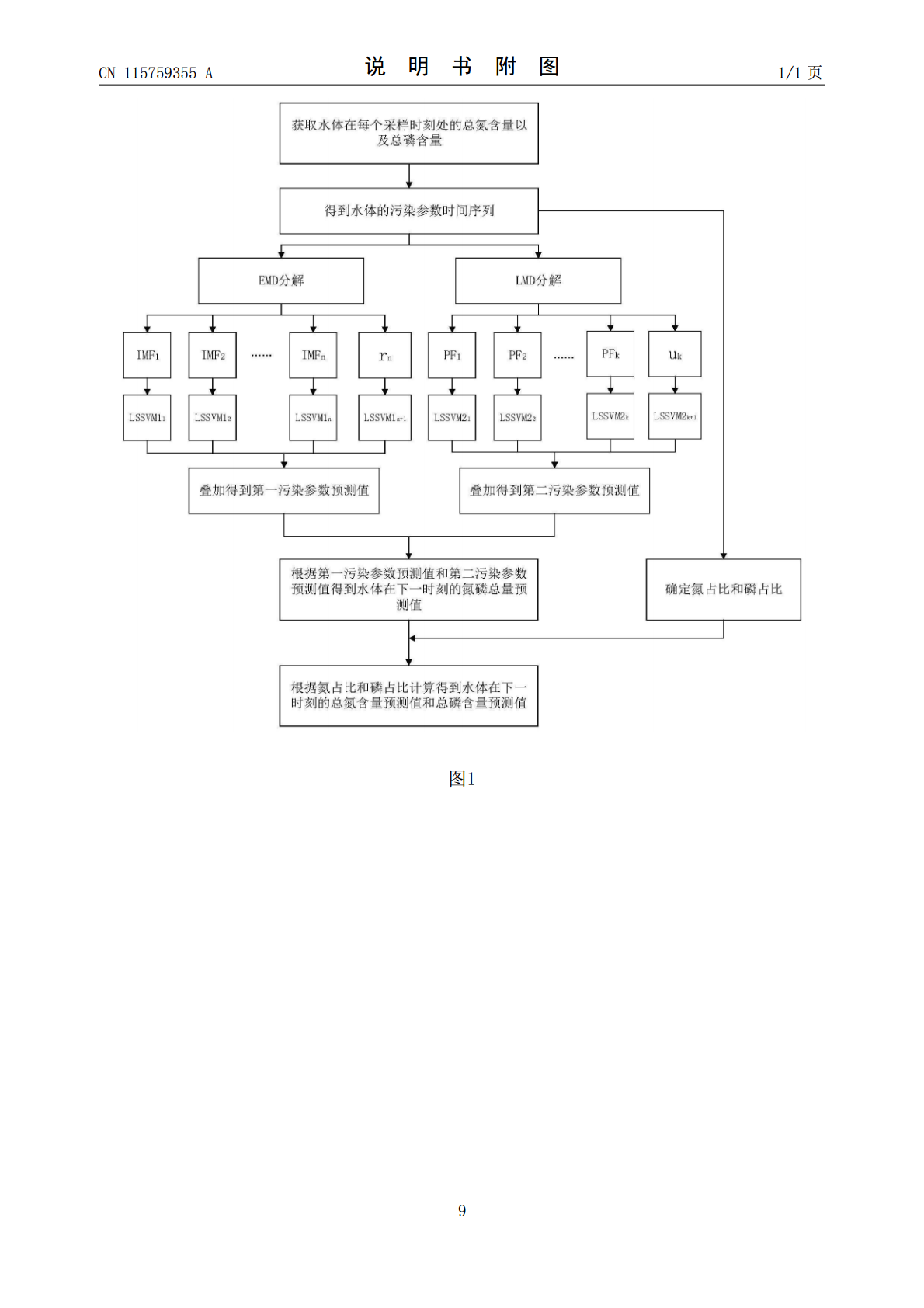
本申请公开了一种基于时间序列的水质预测方法,涉及水质监测领域,该方法以历史采样时刻的污染参数构建污染参数时间序列,结合EMD分解和LMD分解得到不同的分量序列,并利用基于LSSVM模型训练得到的预测模型分别得到各个分量序列的预测结果,继而可以得到下一个采样时刻的污染参数预测值,从而实现水质预测,可以在水污染发生之前实现事前的预测和预防,且采用LSSVM模型可以降低计算复杂度,加快求解速度,并具有较高的预测精度。

基于时间序列的神经网络水质参数预测方法的应用.docx
基于时间序列的神经网络水质参数预测方法的应用基于时间序列的神经网络水质参数预测方法的应用摘要:水环境是人类生活中重要的组成部分,水质参数的准确预测对于水资源的管理和环境保护具有重要意义。传统的水质参数预测方法往往依赖于统计学模型,这些模型无法充分挖掘时间序列数据中的潜在规律和动态变化特征。为此,本文提出了一种基于时间序列的神经网络水质参数预测方法,通过对时间序列数据进行建模和训练,可以更准确地预测水质参数的值。实验结果表明,该方法能够有效提高水质参数预测的准确度和稳定性。1.引言水是地球上最重要的自然资源

基于Box-Jenkins方法的黄河水质时间序列分析与预测.docx
基于Box-Jenkins方法的黄河水质时间序列分析与预测摘要:本文使用Box-Jenkins方法对黄河水质时间序列进行了分析和预测。首先,通过ADF检验和自相关函数(ACF)与偏自相关函数(PACF)分析,确定了时间序列的平稳性和确定了ARIMA模型的阶数。然后,使用Ljung-Box检验进行了模型的检验,并选择最佳模型进行了拟合。接着,通过计算预测误差和画出残差图进行了模型的检验。最后,使用拟合模型对接下来的时间序列进行了预测,并得出结论和建议。1.引言水质是一个国家自然环境的重要组成部分,它对全社会

一种基于压缩感知的时间序列预测方法.docx
一种基于压缩感知的时间序列预测方法基于压缩感知的时间序列预测方法摘要:时间序列预测在许多领域中都具有重要意义,例如金融、气象、交通等。然而,传统的时间序列预测方法在面对高维、长周期的时间序列数据时会遇到一些挑战。为了克服这些挑战,本文提出了一种基于压缩感知的时间序列预测方法。该方法利用压缩感知理论来降低时间序列数据的维度,并结合稀疏表示和重构技术进行预测。实验结果表明,该方法在时间序列预测性能上具有很大优势。关键词:时间序列预测;压缩感知;稀疏表示;重构技术1.引言时间序列预测是通过对历史数据的分析和建模

一种基于时间序列的电力消费预测方法及系统.pdf
本申请提供一种基于时间序列的电力消费预测方法及系统,在实际应用中,首先获取目标省份的原始数据,对所述原始数据做对数运算,获取预处理数据。再对预处理后的电力消费总量数据和地区生产总值数据以及产业结构电力消费数据和产业结构生产总值数据做平稳性检验、协整检验和格兰杰因果检验,获取电力消费和生产总值的协整关系和因果关系。最后建立线性回归模型,获取电力消费总量预测结果。本申请通过分析整体的电力消费与生产总值以及不同产业结构下电力消费和生产总值之间的关系,建立线性回归模型,对电力消费总量进行预测,提高预测准确度。