
一种基于词的短文本摘要抽取方法.pdf

诗文****仙女


1/10

2/10

3/10

4/10

5/10

6/10
7/10

8/10

9/10
10/10
亲,该文档总共11页,到这已经超出免费预览范围,如果喜欢就直接下载吧~
相关资料

一种基于词的短文本摘要抽取方法.pdf
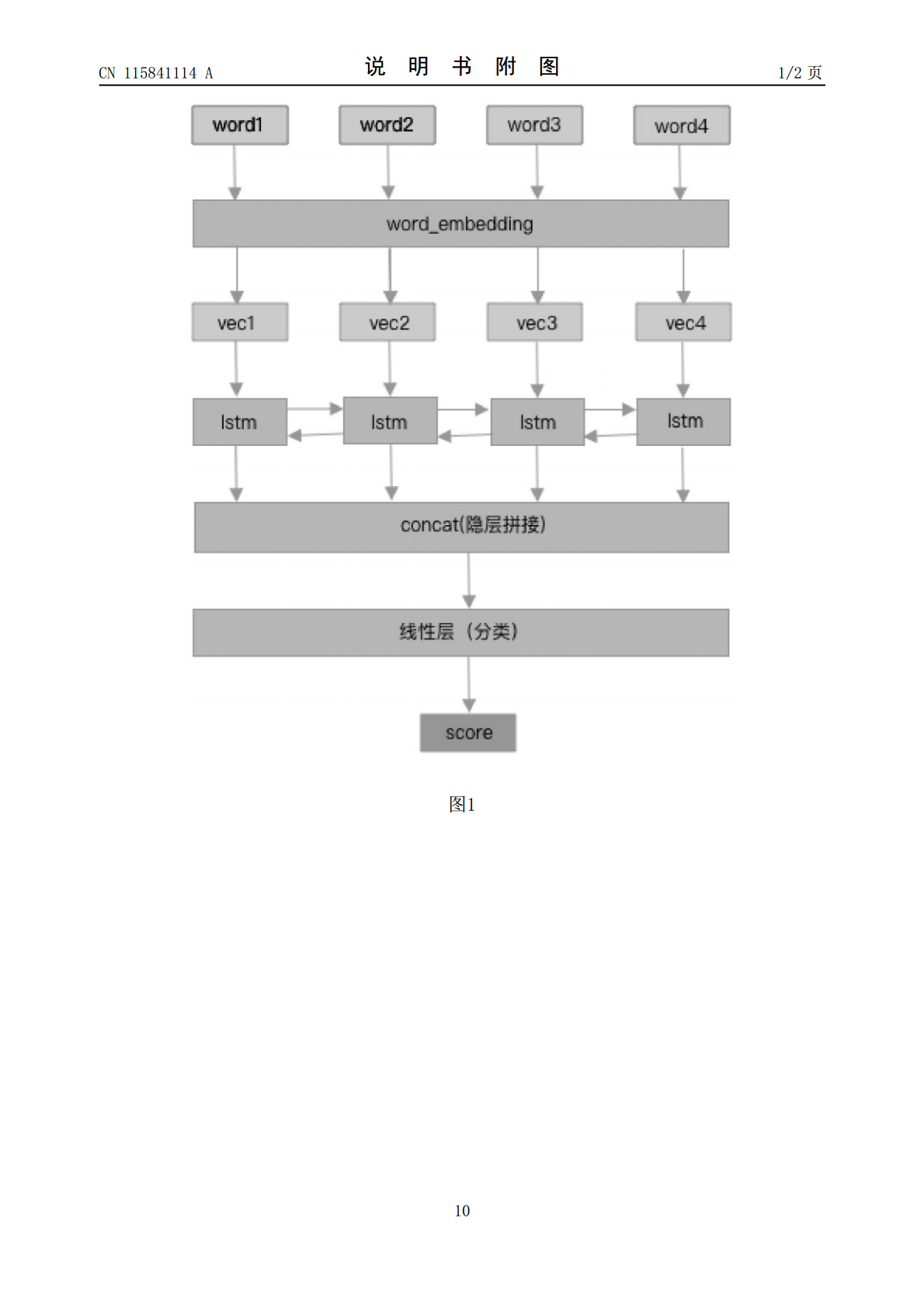
本发明属于NLP领域下文本摘要抽取技术领域,且公开了一种基于词的短文本摘要抽取方法,包括抽取模型和词序模型,所述词序模型步骤如下:第一步:数据标注一;S1.1:选择电销场景下50万对话短文本数据,人工审核纠正每句话的词语顺序;S1.2:使用jieba分词,原始词语顺序的标签为1,然后对每一句话都枚举所有的词语组合,标签为0,最后人工审核纠正所有的标签数据;第二步:数据预处理一。本发明通过抽取模型网络结构中使用膨胀卷积神经网络(DilatedConvolutionNeuralNetwork,DCNN)

一种基于语义匹配的文本摘要自动抽取方法.pdf
一种基于语义匹配的文本摘要自动抽取方法,建立文本摘要抽取模型,抽取文本中的关键语句,利用贪心选择策略,构建候选摘要集,以候选摘要作为抽取单元;其次,对候选摘要集、原始文档和参考摘要文本序列,通过神经主题模型获取文本的主题表征,通过BERT预训练模型获取文本的语言表征;最后,使用语义匹配网络计算候选摘要与原始文档的语义相似度,在输出层中抽取出匹配度最佳的候选摘要。本方法能够利用文本之间的语义关系抽取原始文档中的关键内容,为解决抽取式文本摘要提供了一种可行的途径。

基于集成学习的文本摘要抽取方法研究.pptx
汇报人:CONTENTS集成学习概述集成学习的基本思想集成学习的常见方法集成学习的优势与局限性基于集成学习的文本摘要抽取方法特征选择与提取基分类器选择与训练分类器组合策略性能评估指标实验设计与实现数据集准备实验环境与参数设置实验过程实验结果分析方法比较与讨论与传统文本摘要抽取方法的比较与其他集成学习算法的比较方法优缺点讨论应用场景与展望应用场景分析潜在应用领域研究展望与挑战汇报人:

一种文本摘要抽取方法和装置.pdf
本发明公开了一种文本摘要抽取方法和装置,涉及自然语言处理技术领域。该方法的一具体实施方式包括:将文本中的各个句子转换成语义向量,将所述各个句子的语义向量输入到第一循环神经网络中,以输出所述各个句子的语义表征向量;将所述文本中的各个句子转换成语法结构向量,将所述各个句子的语法结构向量输入到第二循环神经网络中,以输出所述各个句子的结构表征向量;将所述各个句子的语义表征向量和结构表征向量输入到语义结构卷积层中,以输出文本内容向量;将所述文本内容向量输入到第三循环神经网络中,以输出目标句子作为文本摘要。该实施方式

一种对话文本摘要抽取方法和装置.pdf
本发明实施例提供了一种对话文本摘要抽取方法和装置,通过获取包含角色标识的对话文本数据,所述对话文本数据按照对话顺序排列,根据所述对话文本数据生成多个句向量,在所述句向量满足预设条件时确定所述句向量为摘要句,按照所述角色标识和所述对话顺序拼接所述摘要句,得到候选摘要文本。本发明将对话角色信息加入到对话文本数据中,按照对话角色来分句,使获得的对话文本摘要中包括对话角色信息,更适用于对话文本领域,采用二分类的分类方式,判断提取的句向量是否为摘要句,便于模型按照更准确的分类进行预测,进一步地,在拼接摘要句时,按照