
一种计算机辅助医疗数据处理系统及方法.pdf

文库****坚白


1/10

2/10

3/10

4/10

5/10

6/10

7/10

8/10

9/10
10/10
亲,该文档总共11页,到这已经超出免费预览范围,如果喜欢就直接下载吧~
相关资料

一种计算机辅助医疗数据处理系统及方法.pdf
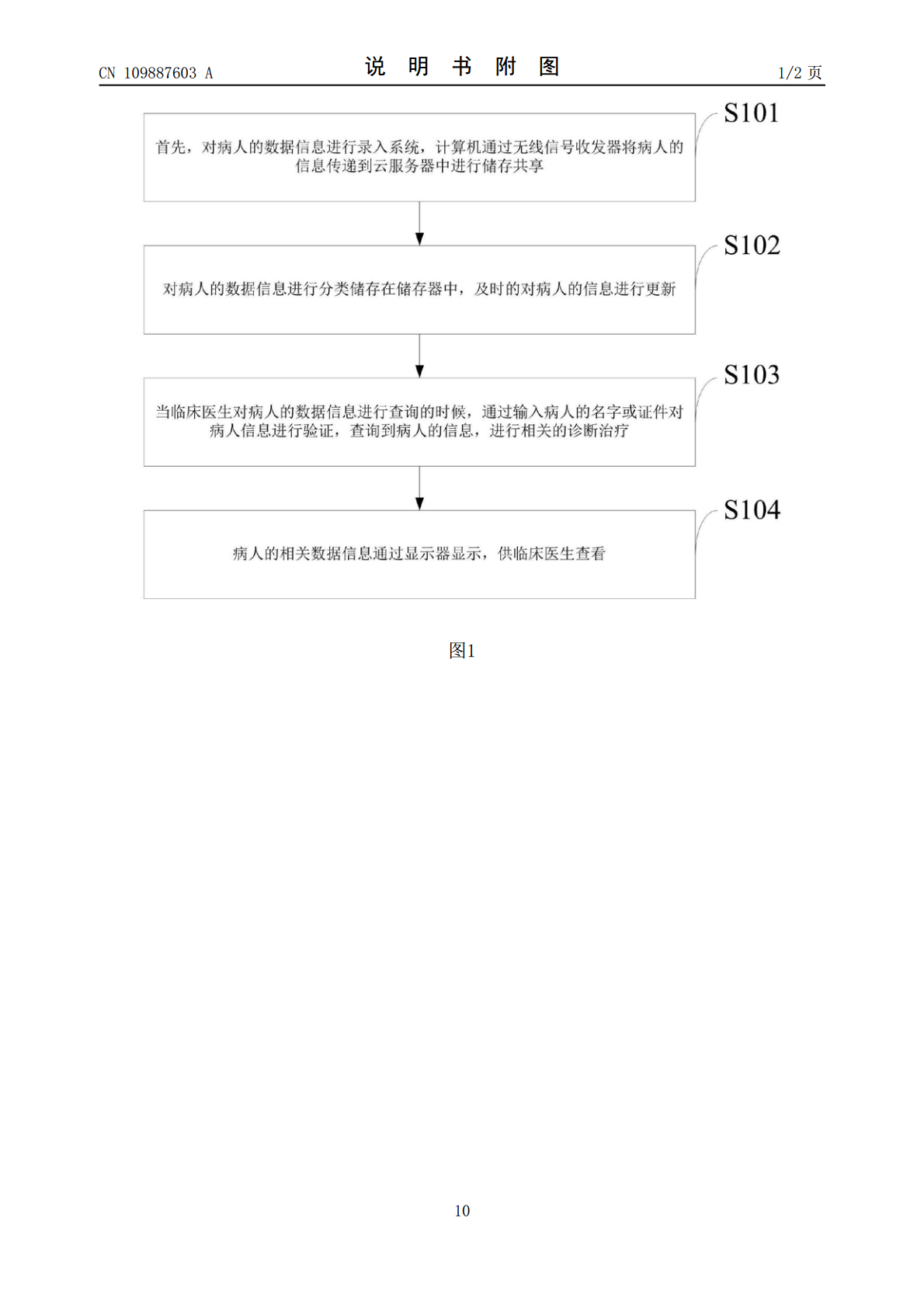
本发明属于医疗辅助技术领域,公开了一种计算机辅助医疗数据处理系统及方法;对病人的数据信息进行录入系统,计算机通过无线信号收发器将病人的信息传递到云服务器中进行储存共享;对病人的数据信息进行分类储存在储存器中,及时的对病人的信息进行更新;当临床医生对病人的数据信息进行查询的时候,通过输入病人的名字或证件对病人信息进行验证,查询到病人的信息,进行相关的诊断治疗;病人的相关数据信息通过显示器显示,供临床医生查看。本发明有效提高SVM算法对少数类的分类性能,提高运行效率;提高挖掘效率和可扩展性,使之适用于动态增长

一种医疗数据处理系统及其方法.pdf
本发明提供了一种医疗数据处理系统及其方法,所述系统包括:医疗设备服务器,连接至LIS系统,用于从所述LIS系统获取样本的信息及操作信息并保存至本地;多个医疗设备组,分别连接至所述医疗设备服务器,其中,所述医疗设备组包括单台医疗设备或医疗设备流水线;用于从所述医疗设备服务器获取所述样本的信息和操作信息,并根据所述操作信息对所述样本进行操作。根据本发明的医疗数据处理系统及其方法,使得任何医疗设备都能够从医疗设备服务器获取相应的样本的信息和操作信息,以实现样本的信息和操作信息与多台仪器进行共享,避免样本的测量结

医疗辅助装置以及医疗辅助方法.pdf
本发明提供医疗辅助装置以及医疗辅助方法。医疗辅助装置具有1个以上的处理器,处理器构成为:取得医疗图像,根据医疗图像,生成用于重叠于医疗图像上的引导显示,该引导显示表示医疗图像中的医疗处置的推荐度的高低不同的段间的边界。

一种基于计算机辅助翻译系统的辅助翻译方法.pdf
本发明提出了一种基于计算机辅助翻译系统的辅助翻译方法,通过设置项目预处理单元、语料库管理单元、系统管理单元、辅助翻译单元、审校管理单元和语料对齐管理单元,对翻译文件进行预处理,进而实现翻译前的工作量统计和分析,从而匹配合适的翻译人员,提高翻译人员利用效率及翻译效率,通过辅助管理、系统管理及审校管理配合使用,进一步提高翻译人员管理效率、翻译效率及翻译准确度,同时通过建立语料库进行语料存储,便于后期直接匹配重复翻译语句,同时通过分级存储,提高翻译文件的安全性。
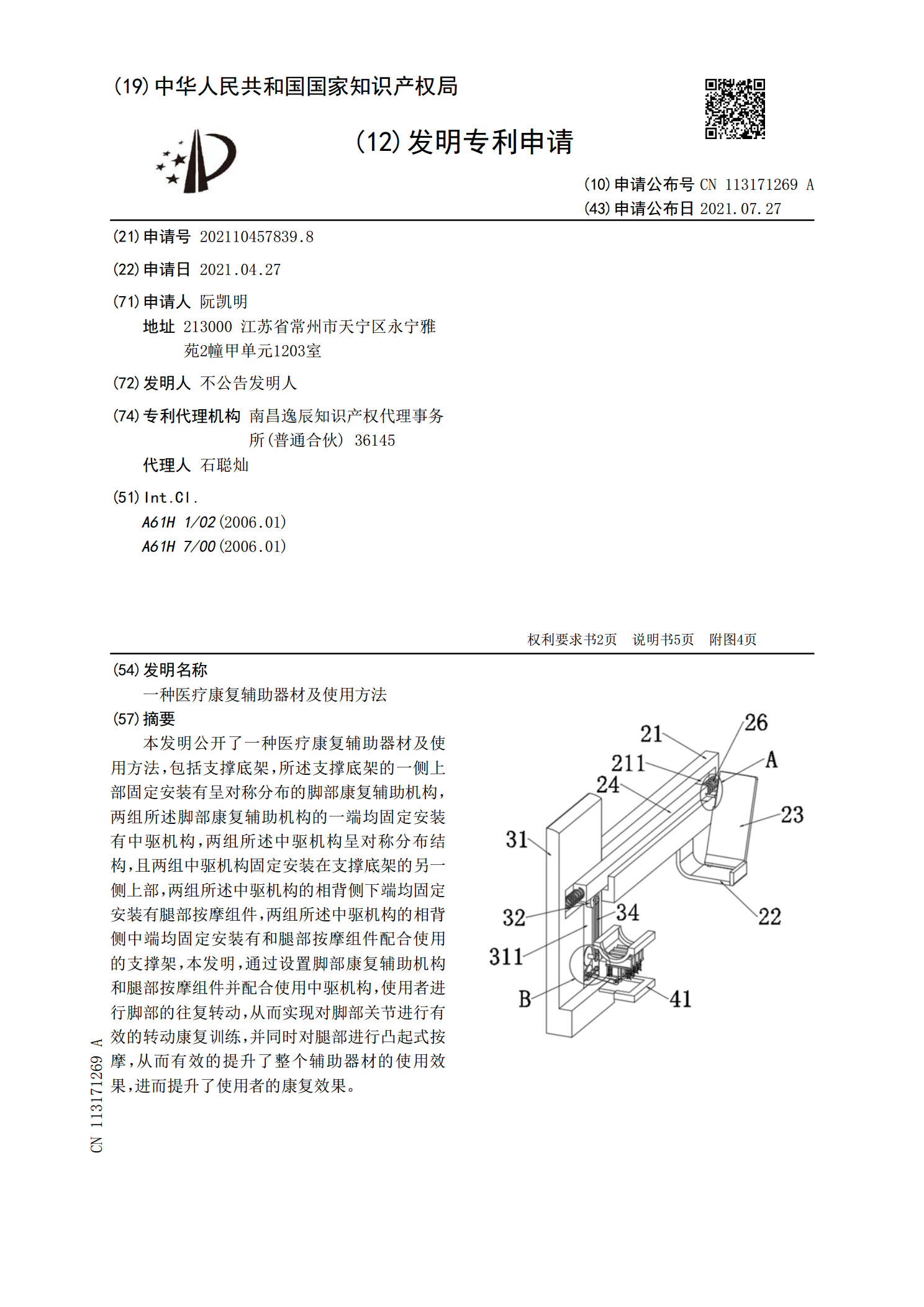
一种医疗康复辅助器材及使用方法.pdf
本发明公开了一种医疗康复辅助器材及使用方法,包括支撑底架,所述支撑底架的一侧上部固定安装有呈对称分布的脚部康复辅助机构,两组所述脚部康复辅助机构的一端均固定安装有中驱机构,两组所述中驱机构呈对称分布结构,且两组中驱机构固定安装在支撑底架的另一侧上部,两组所述中驱机构的相背侧下端均固定安装有腿部按摩组件,两组所述中驱机构的相背侧中端均固定安装有和腿部按摩组件配合使用的支撑架,本发明,通过设置脚部康复辅助机构和腿部按摩组件并配合使用中驱机构,使用者进行脚部的往复转动,从而实现对脚部关节进行有效的转动康复训练,