
基于Spark的异构集群调度策略研究.pdf

淑然****by


1/10

2/10

3/10

4/10

5/10

6/10
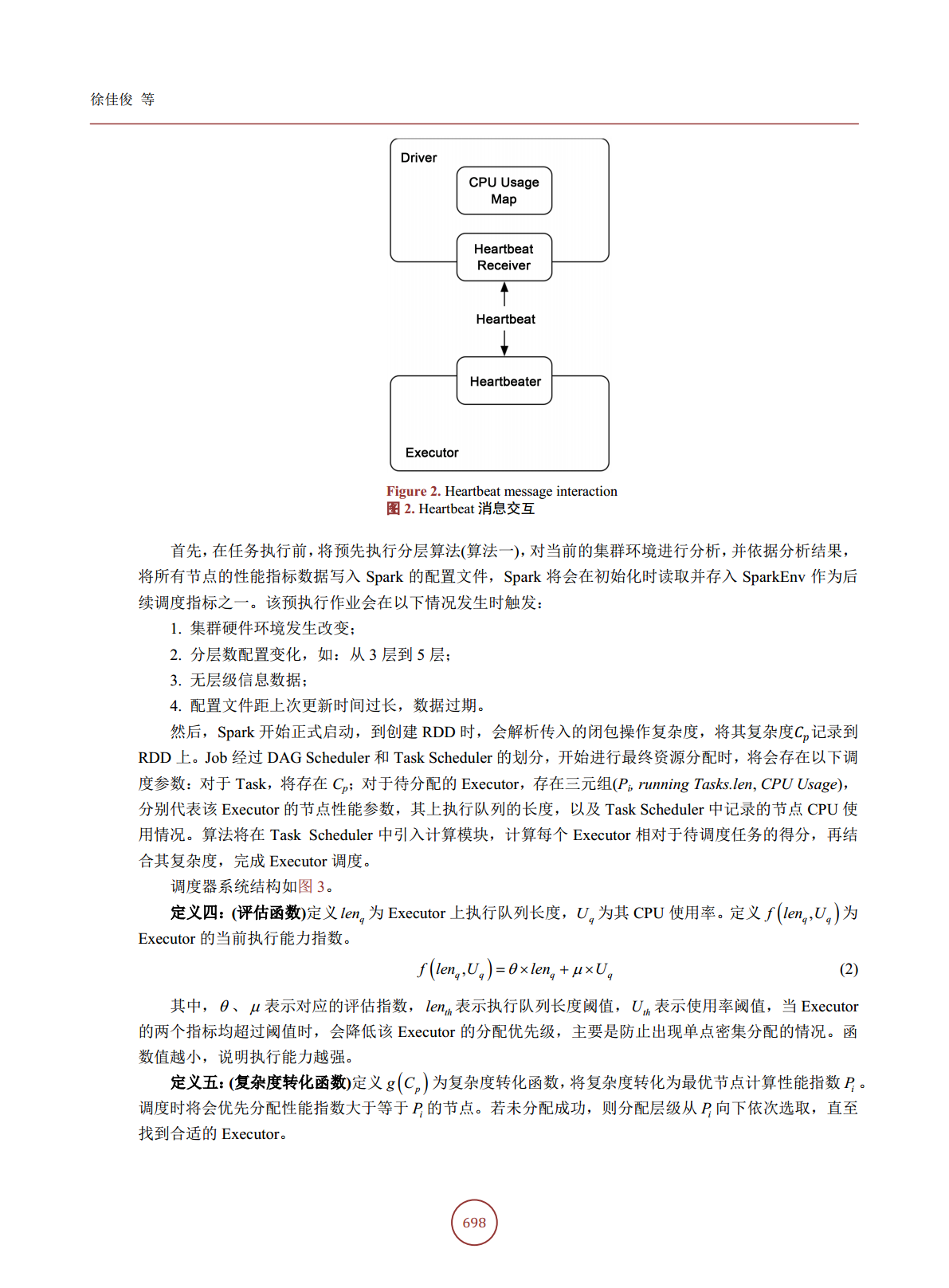
7/10

8/10

9/10

10/10
亲,该文档总共13页,到这已经超出免费预览范围,如果喜欢就直接下载吧~
相关资料

基于Spark的异构集群调度策略研究.pdf
ComputerScienceandApplication计算机科学与应用20166(11)692-704PublishedOnlineNovember2016inHans.http://www.hanspub.org/journal/csahttp://dx.doi.org/10.12677/csa.2016.611084AdaptiveSchedulingStrategyfor

基于Hadoop异构集群的动态作业调度研究.docx
基于Hadoop异构集群的动态作业调度研究摘要:随着云计算和大数据技术的发展,Hadoop作为目前最流行的大数据处理框架之一,已经被广泛应用于各种领域。然而,由于传统Hadoop集群采用的是同构计算节点,导致资源利用率较低,性能瓶颈难以突破。为此,本文提出了一种基于Hadoop异构集群的动态作业调度策略,旨在提高集群资源利用率和作业执行性能。该策略通过智能识别和分配任务给不同类型计算节点,实现异构资源的合理利用,并根据任务的执行情况动态调整节点的负载均衡,以达到动态作业调度的目的。通过对该策略进行实验验证

基于Spark平台的资源调度策略研究现状.docx
基于Spark平台的资源调度策略研究现状基于Spark平台的资源调度策略研究现状摘要:随着大数据时代的到来,ApacheSpark成为了处理大规模数据的主要框架之一。为了充分利用集群资源,提高Spark应用程序的性能,研究人员对基于Spark平台的资源调度策略进行了广泛的探索和研究。本论文综述了目前基于Spark平台的资源调度策略的研究现状,包括静态分配和动态调整两个方面,并提出了一些可能的研究方向和改进。1.引言随着大数据处理需求的不断增长,ApacheSpark作为一种高性能的分布式计算框架被广泛应用

一种基于深度强化学习和异构Spark集群的节能调度方法及系统.pdf
本发明属于强化学习和大数据处理领域,具体涉及一种基于深度强化学习和异构Spark集群的节能调度方法及系统;该方法包括:实时获取Spark集群上真实负载下的在线数据信息,将数据信息输入到训练好的Q网络,Q网络对数据信息进行能耗‑时间目标预测,系统根据能耗‑时间目标预测选择能耗‑时间目标最低的方案进行资源分配;本发明考虑到集群异构导致能耗不同从而带来的资源优先分配问题,在保证满足用户响应时间情况下寻找最低能耗‑时间目标,并根据最低能耗‑时间目标进行资源调度,能针对能耗目标或者多种SLA目标进行优化并尽可能的节

基于Hadoop异构集群的动态作业调度研究的任务书.docx
基于Hadoop异构集群的动态作业调度研究的任务书一、选题背景及意义随着大数据时代的到来,Hadoop作为一种广泛应用的分布式计算框架,已被广泛应用于各种大规模数据处理场景。Hadoop的主要优势在于它可以处理海量数据,其分布式计算模型也可以通过添加更多节点来扩展计算能力。然而,随着数据量和计算量的增加,Hadoop集群的负载也会越来越高,而且现有的Hadoop调度器并不能根据异构集群的特点适应负载增加和特殊计算场景的需求。为了解决这一问题,基于Hadoop异构集群的动态作业调度成为了一个研究热点。本文的