
一种基于对偶学习的音频-图像跨模态检索方法.pdf

是你****芹呀


1/10

2/10

3/10

4/10

5/10

6/10

7/10

8/10
9/10
10/10
亲,该文档总共11页,到这已经超出免费预览范围,如果喜欢就直接下载吧~
相关资料

一种基于对偶学习的音频-图像跨模态检索方法.pdf
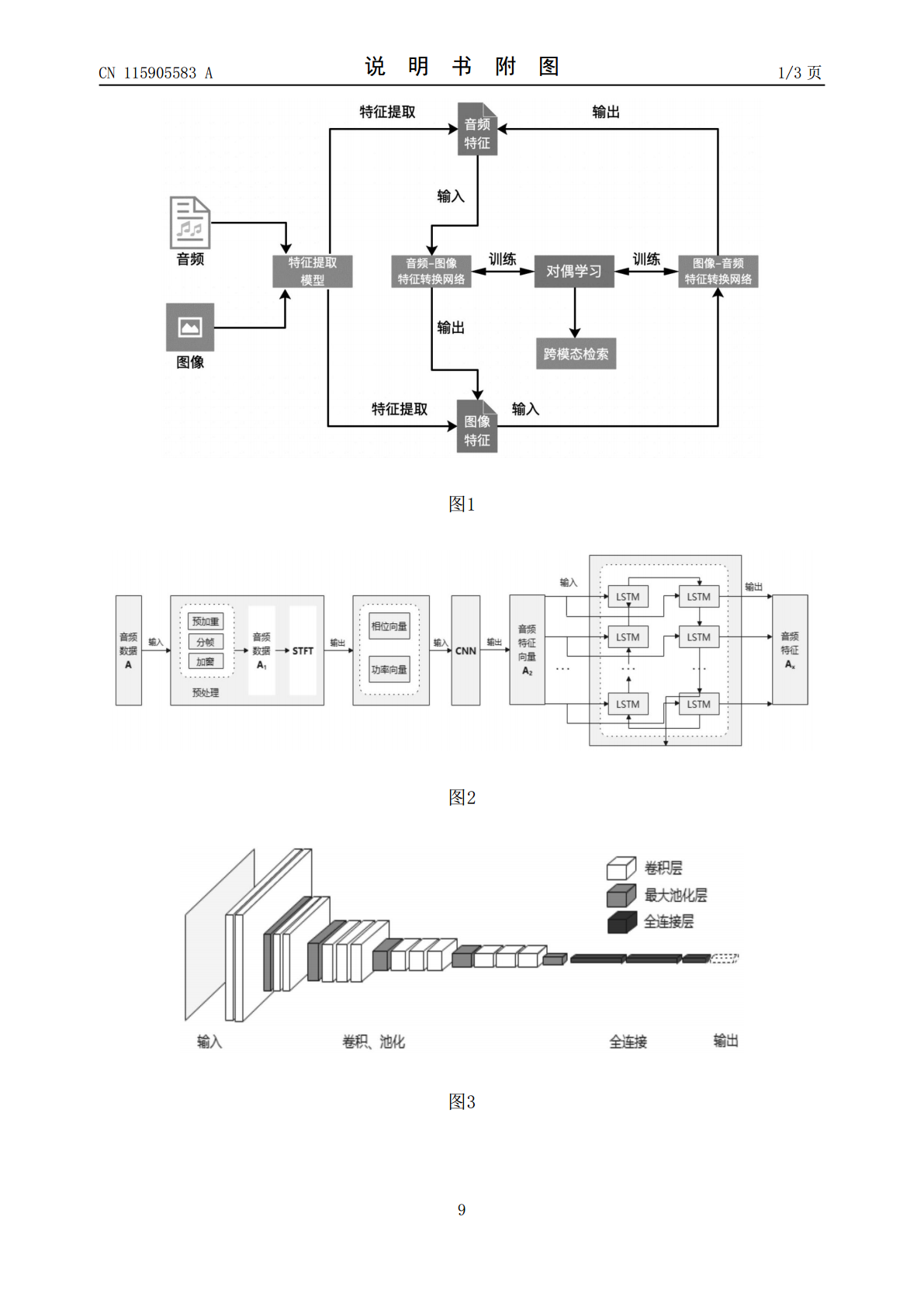
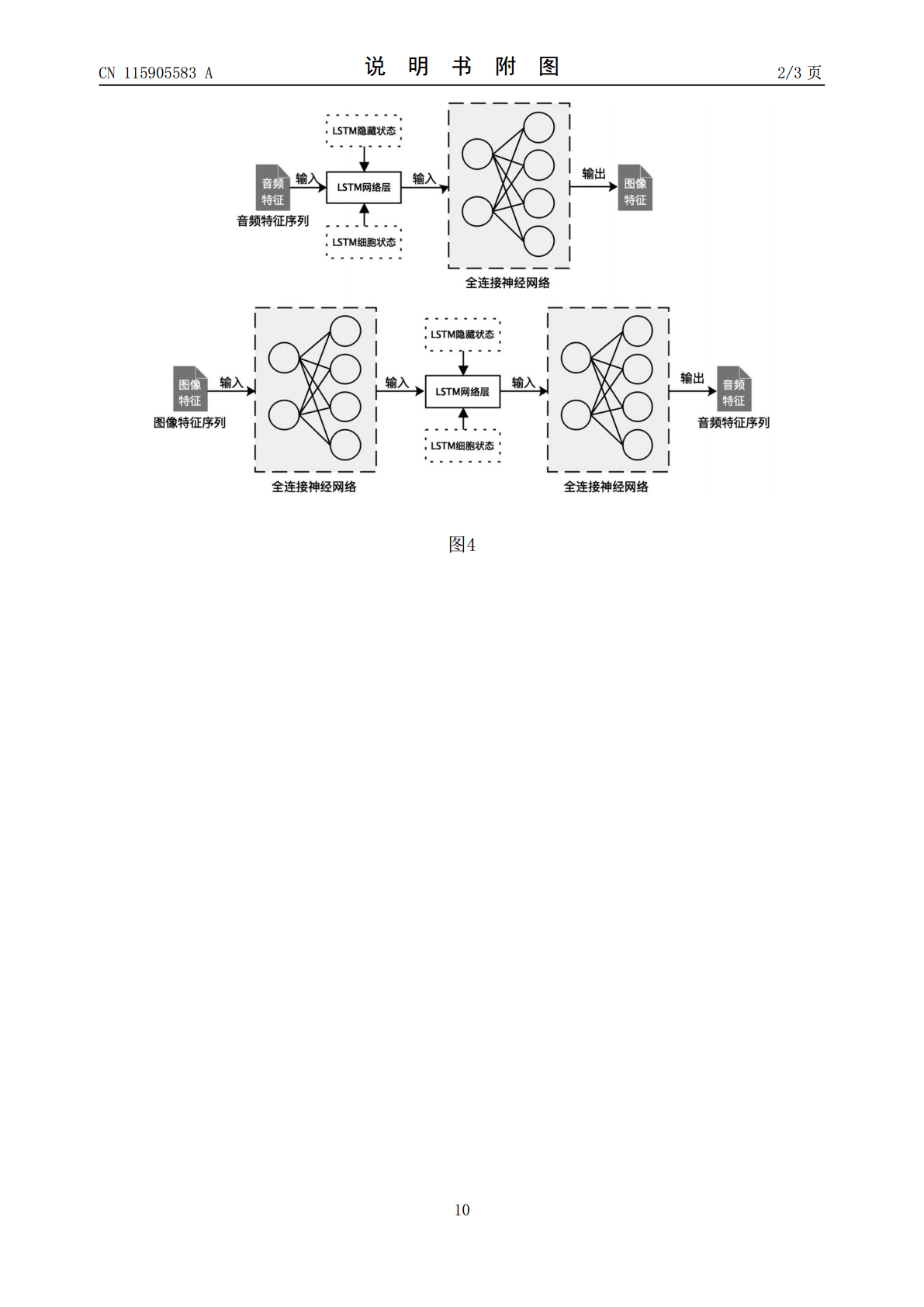
本发明属于深度学习技术领域,涉及一种基于对偶学习的音频‑图像跨模态检索方法。本发明实现了一种音频‑图像的跨模态检索,解决使用传统机器学习方法多模态数据对应关系难以标注的问题。在数据特征提取中,VGG采用小的卷积核和池化层,层数更深,通道数更多,而更多的通道数表示更丰富的图像特征,同时,通道数的增加,使得更多的信息可以被提取出来。构建了特征转换神经网络,将对偶学习引入模型学习,将两个跨模态任务进行训练,为跨模态数据的深度学习方法提供了新思路。

基于跨模态技术的商品图像检索方法研究的开题报告.docx
基于跨模态技术的商品图像检索方法研究的开题报告一、研究背景及意义在当前庞大的电商市场中,商品图片数量非常庞大,面对如此庞大的商品数据,传统的基于关键词的图像检索方法常常不能满足精准的检索需求。因此,基于跨模态技术的商品图像检索已经成为当今商品搜索领域中的研究热点。跨模态技术是一种能够将不同类型的信息或数据转换为同一表示形式的技术,常见的跨模态应用包括图像检索、语音识别、视频分析等领域。本研究旨在研究并应用跨模态技术,通过建立有效的商品图像检索模型,提高商品搜索精度,从而为电商平台带来更好的用户体验,提高平

基于深度学习的特种车辆跨模态检索方法.pptx
汇报人:CONTENTS添加章节标题跨模态检索方法概述跨模态检索的概念和意义跨模态检索的方法和流程跨模态检索的应用场景和优势基于深度学习的跨模态检索方法深度学习在跨模态检索中的应用基于深度学习的跨模态检索模型深度学习模型的训练和优化特种车辆跨模态检索的挑战和解决方案特种车辆跨模态检索的难点和挑战针对特种车辆的特点和需求的解决方案解决特种车辆跨模态检索问题的关键技术基于深度学习的特种车辆跨模态检索方法实现数据预处理和特征提取模型训练和优化过程检索结果的评价和展示案例分析和应用效果评估案例介绍和分析应用效果评

基于深度学习的跨模态音频情感分类方法研究.docx
基于深度学习的跨模态音频情感分类方法研究基于深度学习的跨模态音频情感分类方法研究摘要:随着人们对情感分析和情感识别的需求不断增加,音频情感分类也成为一个热门研究领域。然而,传统的音频情感分类方法在特征提取和模型构建方面仍然存在一些问题。为解决这些问题,本论文提出了一种基于深度学习的跨模态音频情感分类方法。该方法利用深度卷积神经网络(DCNN)和长短时记忆网络(LSTM)来提取音频的语义信息,并通过多模态融合方法将音频情感分析与其他模态的情感信息相结合。实验结果表明,所提出的方法在音频情感分类任务上取得了较

基于多任务学习的图像和文本跨模态哈希检索研究.docx
基于多任务学习的图像和文本跨模态哈希检索研究基于多任务学习的图像和文本跨模态哈希检索研究摘要:在现代社会中,信息爆炸的问题越来越突出,如何高效地检索到所需的信息成为一个重要的问题。图像和文本是两种常见的信息形式,跨模态哈希检索是一种将图像和文本映射到同一空间的技术,使得可以通过一种模态的数据来检索到另一种模态的数据。本文提出了一种基于多任务学习的图像和文本跨模态哈希检索方法,该方法结合图像和文本的语义信息,并利用多任务学习的能力进行端到端的训练。实验结果表明,该方法在图像和文本跨模态哈希检索任务上取得了良