
基于多模态语义嵌入的人体动作识别方法及系统.pdf

纪阳****公主


1/10

2/10

3/10

4/10

5/10

6/10

7/10

8/10

9/10
10/10
在线预览结束,喜欢就下载吧,查找使用更方便
相关资料

基于多模态语义嵌入的人体动作识别方法及系统.pdf
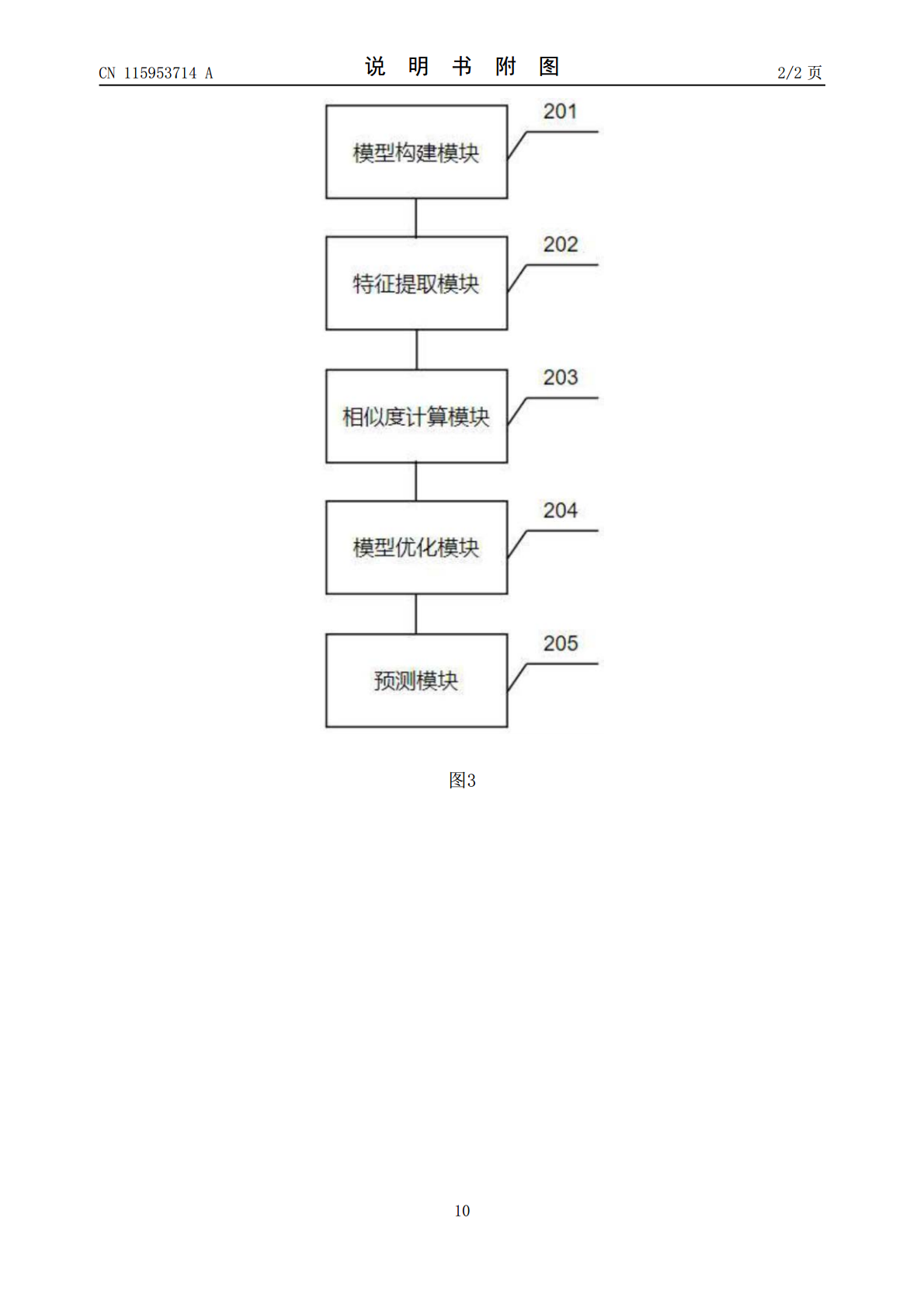
本发明涉及一种基于多模态语义嵌入的人体动作识别方法及系统,该方法包括:构建网络模型,其中包括一个用于提取视频时空特征的视频编码器和一个用于提取视频标签文本特征的文本编码器;提取视频中的时空特征以及视频标签中的文本特征,分别将时空特征和文本特征映射到一个公共空间;通过相似度计算模块,计算出两种模态之间的对称相似性得分;之后利用Kullback‑Leibler(KL)散度计算对比损失,对网络模型进行优化,使成对视频和标签表示相互靠近;利用所述优化后的模型对人体动作视频进行预测。本发明通过引入文本模态的信息,将

基于局部语义的人体动作识别方法.docx
基于局部语义的人体动作识别方法标题:基于局部语义的人体动作识别方法摘要:随着计算机视觉和深度学习的快速发展,人体动作识别在许多应用领域中变得越来越重要。传统的动作识别方法通常通过提取人体关键点或骨架信息,并应用机器学习算法来识别特定的动作。然而,这些传统方法在遇到复杂的场景、姿态变化和遮挡等问题时表现不佳。为了克服这些问题,本文提出了一种基于局部语义的人体动作识别方法。该方法通过从局部区域提取特征,并应用深度学习模型来学习局部语义信息,从而提高动作识别的准确性和鲁棒性。1.引言人体动作识别在许多领域中具有

基于多语义多模态信息的行为识别方法及装置.pdf
本发明公开了一种基于多语义多模态信息的行为识别方法及装置,该方法包括:通过摄像设备获取视频数据集合,并根据光流算法对视频数据集合中的每一个视频数据的帧数据集合进行计算,得到帧数据集合中每一个行为动作的关键帧数据以及关键帧数据的光流信息,将视频数据集合中的所有视频数据的关键帧数据以及关键帧数据的光流信息输入至深度学习网络,并通过深度学习网络提取出所有视频数据的初始特征值集合,将初始特征值集合输入至对应的语义识别网络,通过语义识别网络提取出对应的语义特征信息,并将语义特征信息输入至行为识别网络,通过行为识别网

基于异构多流网络的多模态人体动作识别.docx
基于异构多流网络的多模态人体动作识别基于异构多流网络的多模态人体动作识别摘要:多模态人体动作识别是计算机视觉和机器学习领域的重要研究方向。在这篇论文中,我们提出了一种基于异构多流网络的多模态人体动作识别方法。该方法通过结合视觉和语音信息来提升动作识别的准确性。我们使用了一个包含视频和音频流的异构多流模型,通过联合训练来融合两种信息。实验证明,我们的方法在多模态人体动作识别任务上取得了优于传统方法的结果。1.引言人体动作识别作为计算机视觉领域的一个重要问题,已经得到了广泛的研究。传统的方法主要是使用视频流数

基于骨架语义图式的人体动作识别方法研究.docx
基于骨架语义图式的人体动作识别方法研究基于骨架语义图式的人体动作识别方法研究摘要:人体动作识别是计算机视觉和模式识别领域的一个重要研究方向。本文研究了基于骨架语义图式的人体动作识别方法,在解决人体动作识别中存在的问题方面取得了一定的成果。首先,本文对人体动作识别的背景和意义进行了阐述;然后,详细介绍了基于骨架语义图式的人体动作识别方法的研究思路和流程;最后,通过实验验证了该方法的有效性和准确性。实验结果表明,基于骨架语义图式的人体动作识别方法能够有效地提取和利用人体骨架信息,对于不同的人体动作进行准确的识