
一种基于抽象语法树的软件缺陷预测方法.pdf

mm****酱吖


1/10

2/10

3/10

4/10

5/10

6/10

7/10

8/10
9/10
10/10
在线预览结束,喜欢就下载吧,查找使用更方便
相关资料

一种基于抽象语法树的软件缺陷预测方法.pdf
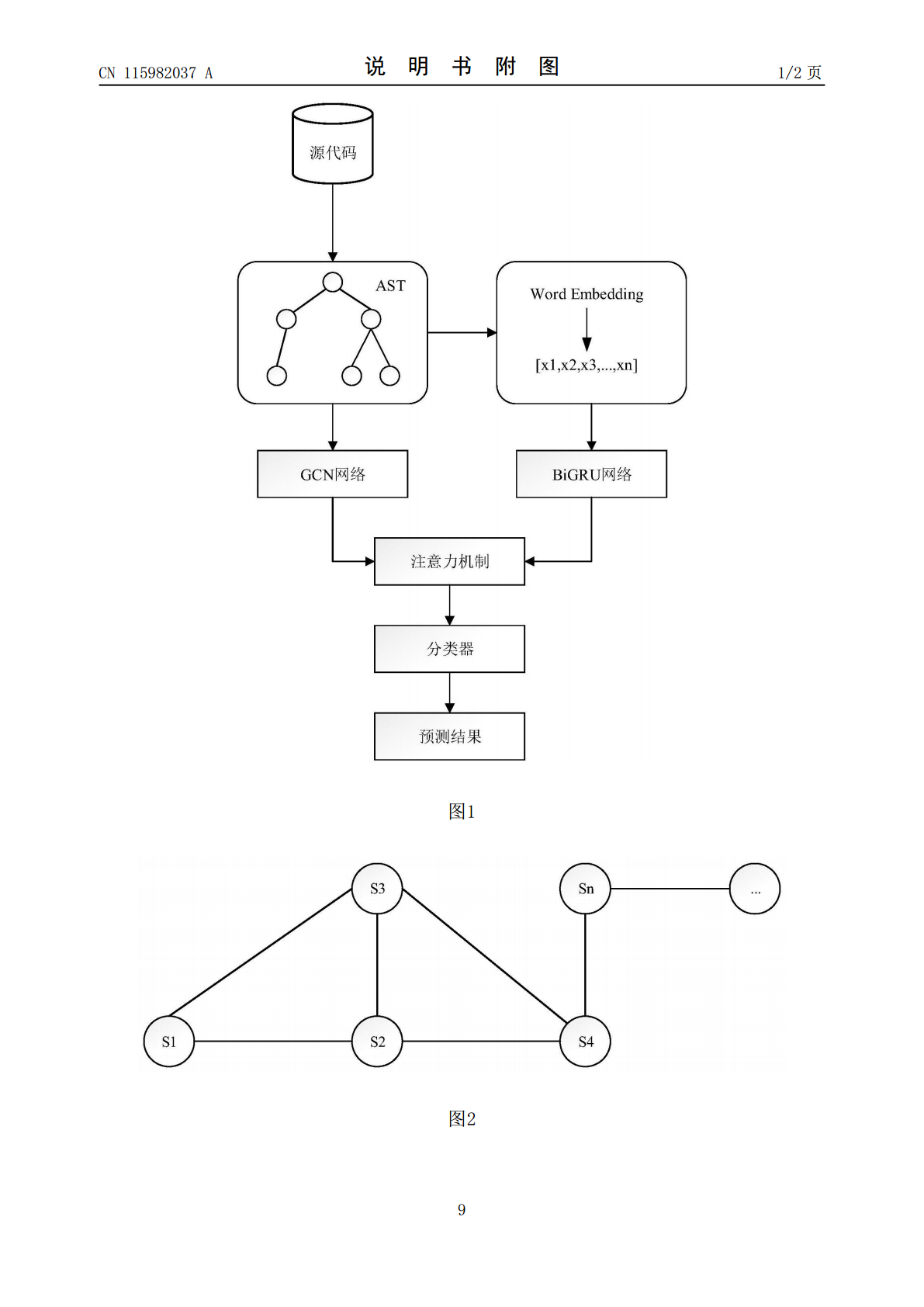
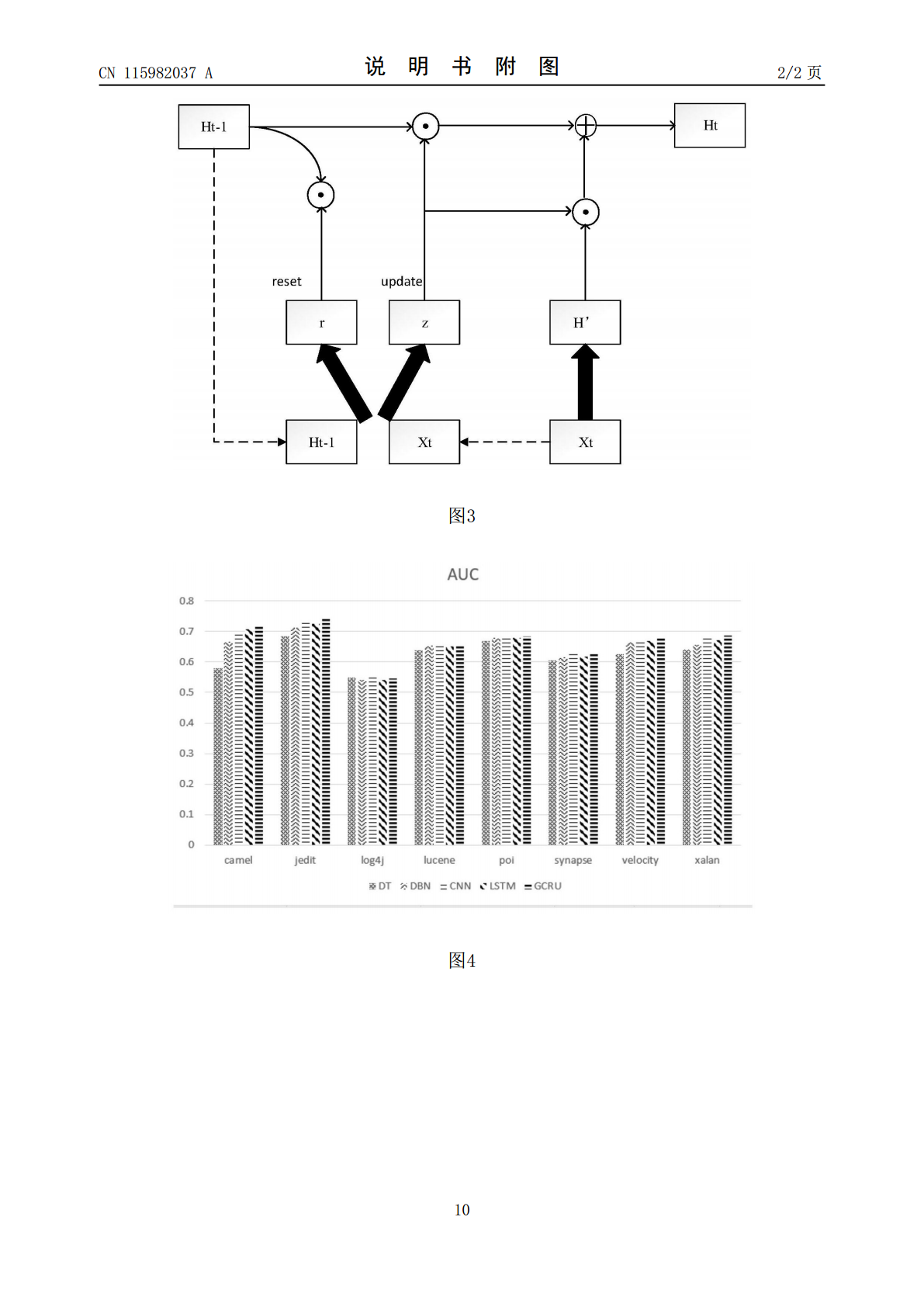
本发明提供了一种基于抽象语法树的软件缺陷预测方法,属于深度学习领域和软件缺陷预测领域。本发明通过将源代码转换为抽象语法树的形式,保留其定义良好的结构信息与语义信息,使用图卷积网络(GCN)来学习语法树结构中的节点的特征和网络结构的信息;使用词嵌入将抽象语法树的节点序列转换成文本向量,然后使用BiGRU网络来学习上下文直接的语义关系以提取语义特征,最后将得到的两类特征基于注意力机制进行聚合得到代码的特征,将其输入分类器中以预测缺陷率。本发明充分利用了代码的语义和语法特征使用注意力机制为不同变量赋予不同的权重

基于抽象语法树的软件缺陷自动分类的任务书.docx
基于抽象语法树的软件缺陷自动分类的任务书任务书:基于抽象语法树的软件缺陷自动分类任务背景随着软件系统的不断复杂化和功能丰富化,软件缺陷问题也越来越多,并且难以有效地检测和修复。因此,建立一种自动化的软件缺陷分类方法,具有重要的意义,可以有效地加快软件缺陷的识别和解决速度,提高软件开发和维护的效率。而基于抽象语法树的软件缺陷自动分类技术,是一种先进的软件缺陷分类方法,它可以全面、细致地对代码进行分析,自动识别各类常见的软件缺陷,并且可以快速地提供解决方案,帮助软件开发人员快速解决软件缺陷问题。任务目标本任务

基于抽象语法树的代码生成方法及系统.pdf
本发明提出了一种基于抽象语法树的代码生成方法及系统,其中方法包括,操作系统将所述配置文件读入到系统的内存中用以进行调用;配置文件包含:基础文件地址信息与目标生成内容的配置信息;获取到的基础文件中的文本内容解析为元数据;基于元数据生成抽象语法树;同时调用所述目标生成内容的配置信息,基于所述目标生成内容的配置信息从所述抽象语法树中提取目标生成内容;基于所述目标生成内容生成目标代码;本发明实施方式可以节省处理时间,提高代码生成效率。

基于抽象语法树的前端埋点方法及装置.pdf
本申请提供了一种基于抽象语法树的前端埋点方法及装置,可用于金融领域或其他领域,该方法包括:将代码源文件转化为与所述代码源文件对应的第一AST;对埋点进行全局初始化,所述全局初始化至少包括配置埋点上送地址、生成采集事件清单以及生成埋点上送函数;根据所述采集事件清单,对所述第一AST中的与事件对应的节点进行识别;根据所述第一AST的节点信息中的原始函数名称和文件路径,构造埋点逻辑代码;将所述埋点逻辑代码转换为与所述埋点逻辑代码对应的第二AST;以及将所述第二AST添加至所述第一AST的头部。本申请能够无需人工

基于抽象语法树的安卓代码异味的重构方法研究.docx
基于抽象语法树的安卓代码异味的重构方法研究标题:基于抽象语法树的安卓代码异味的重构方法研究摘要:随着移动应用的普及,安卓平台上的应用代码呈现出快速增长的趋势。然而,大量的代码可能会导致代码异味的出现,使得代码难以理解、扩展及维护。本文通过研究使用抽象语法树的方法来识别和重构安卓代码中的异味问题。针对常见的代码异味类型,如代码重复、长方法、长类等,提出了相应的重构方法并进行了实证研究。研究表明,基于抽象语法树的重构方法可以有效地提高代码的可读性、可维护性和性能。1.引言随着移动应用的广泛应用,安卓平台上的代