
Spark Streaming.docx

小忆****ng


1/10

2/10
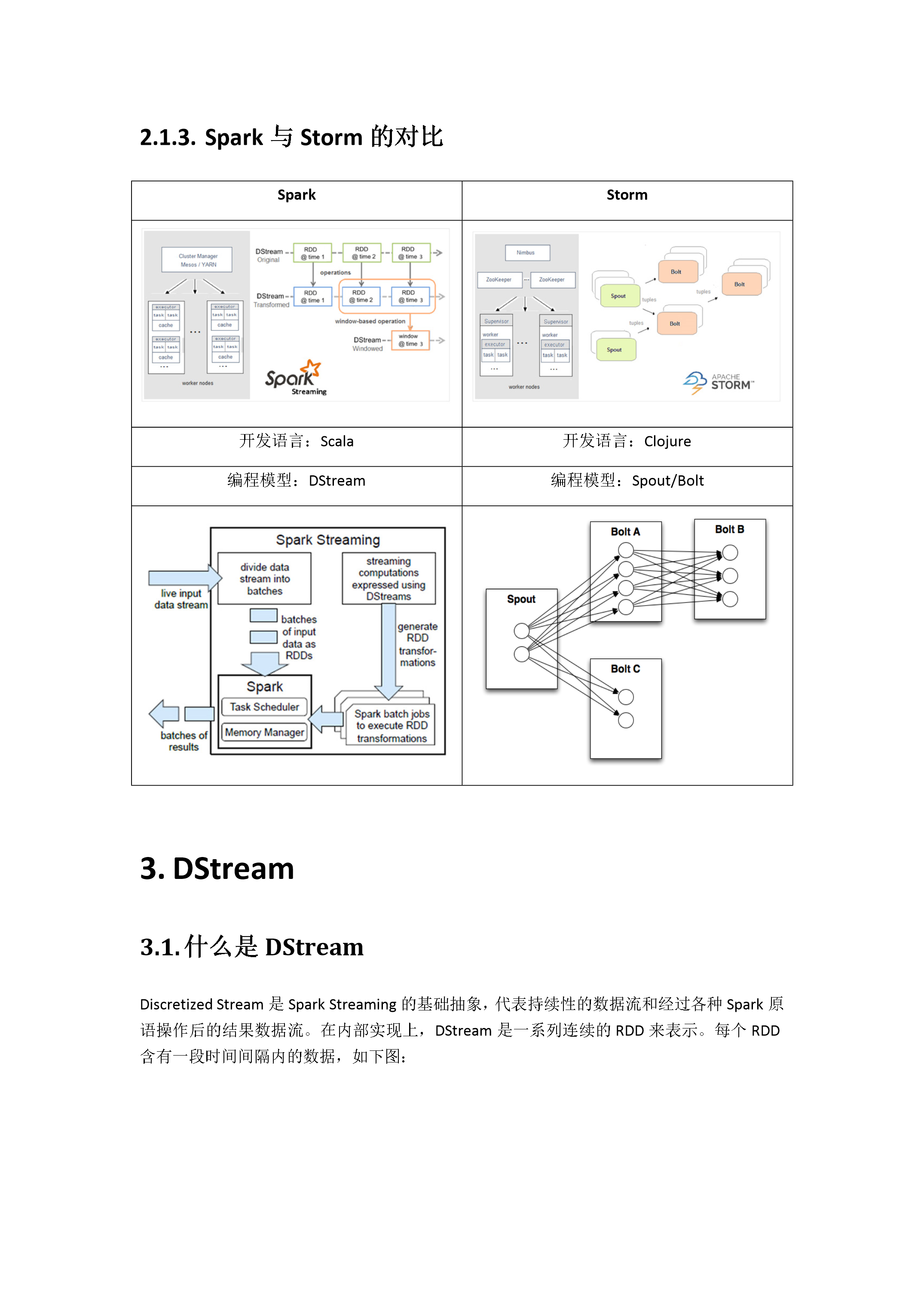
3/10

4/10
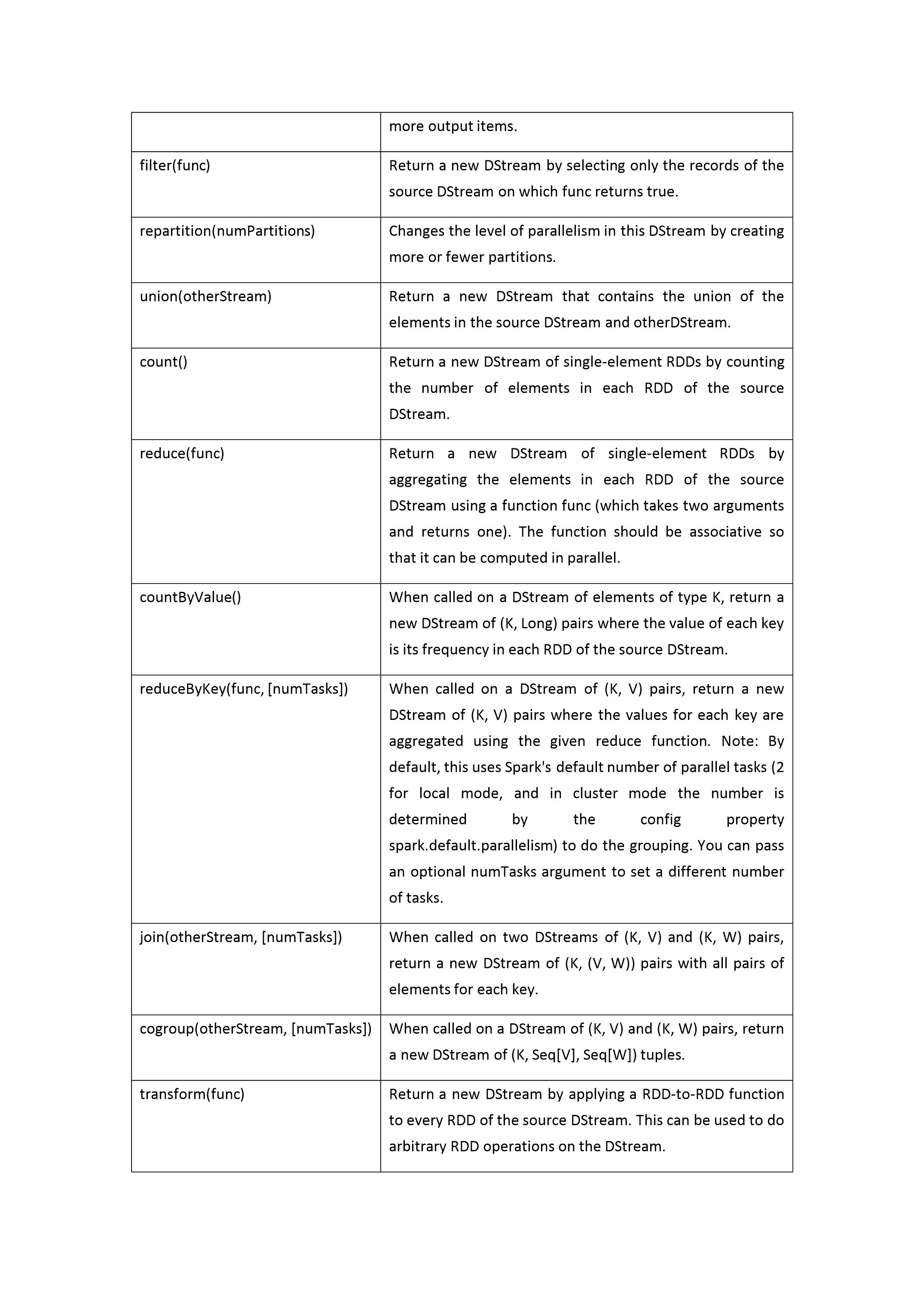
5/10

6/10

7/10

8/10
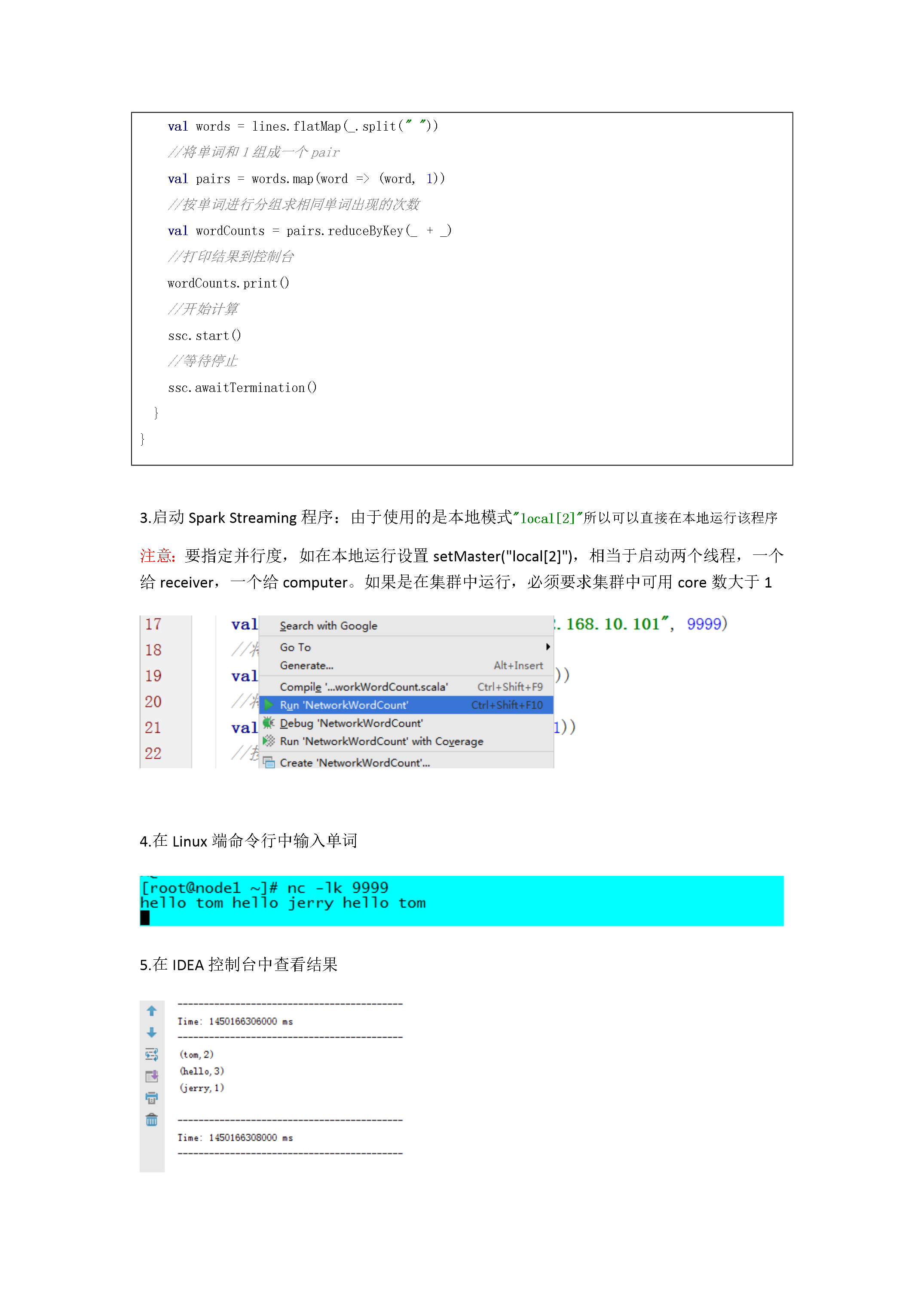
9/10
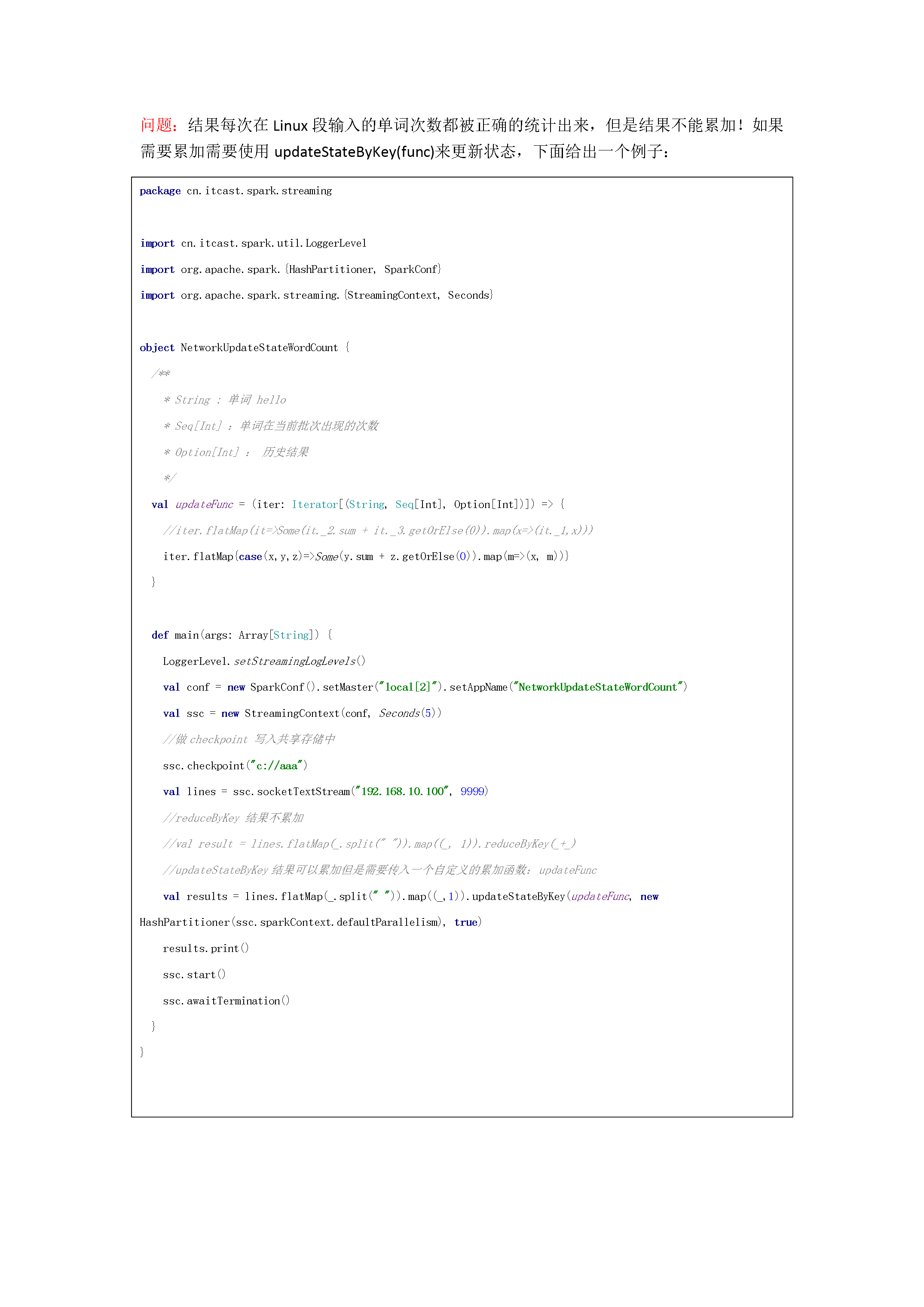
10/10
亲,该文档总共12页,到这已经超出免费预览范围,如果喜欢就直接下载吧~
相关资料

Spark Streaming.docx
SparkStreaming课程目标掌握SparkStreaming的原理熟练使用SparkStreaming完成流式计算任务SparkStreaming介绍SparkStreaming概述什么是SparkStreamingSparkStreaming类似于ApacheStorm,用于流式数据的处理。根据其官方文档介绍,SparkStreaming有高吞吐量和容错能力强等特点。SparkStreaming支持的数据输入源很多,例如:Kafka、Flume、Twitter、ZeroMQ和简单的TCP套接字等
Spark Streaming.docx
SparkStreaming课程目标掌握SparkStreaming的原理熟练使用SparkStreaming完成流式计算任务SparkStreaming介绍SparkStreaming概述什么是SparkStreamingSparkStreaming类似于ApacheStorm,用于流式数据的处理。根据其官方文档介绍,SparkStreaming有高吞吐量和容错能力强等特点。SparkStreaming支持的数据输入源很多,例如:Kafka、Flume、Twitter、ZeroMQ和简单的TCP套接字等

Spark Streaming.docx
SparkStreaming课程目标掌握SparkStreaming的原理熟练使用SparkStreaming完成流式计算任务SparkStreaming介绍SparkStreaming概述什么是SparkStreamingSparkStreaming类似于ApacheStorm,用于流式数据的处理。根据其官方文档介绍,SparkStreaming有高吞吐量和容错能力强等特点。SparkStreaming支持的数据输入源很多,例如:Kafka、Flume、Twitter、ZeroMQ和简单的TCP套接字等

Spark Streaming.docx
SparkStreaming课程目标掌握SparkStreaming的原理熟练使用SparkStreaming完成流式计算任务SparkStreaming介绍SparkStreaming概述什么是SparkStreamingSparkStreaming类似于ApacheStorm,用于流式数据的处理。根据其官方文档介绍,SparkStreaming有高吞吐量和容错能力强等特点。SparkStreaming支持的数据输入源很多,例如:Kafka、Flume、Twitter、ZeroMQ和简单的TCP套接字等

Spark Streaming.docx
SparkStreaming课程目标掌握SparkStreaming的原理熟练使用SparkStreaming完成流式计算任务SparkStreaming介绍SparkStreaming概述什么是SparkStreamingSparkStreaming类似于ApacheStorm,用于流式数据的处理。根据其官方文档介绍,SparkStreaming有高吞吐量和容错能力强等特点。SparkStreaming支持的数据输入源很多,例如:Kafka、Flume、Twitter、ZeroMQ和简单的TCP套接字等