
一种基于ALBERT和LDA的跨域情感分类方法.pdf

志信****pp


1/8

2/8

3/8

4/8

5/8

6/8

7/8
8/8
在线预览结束,喜欢就下载吧,查找使用更方便
相关资料

一种基于ALBERT和LDA的跨域情感分类方法.pdf
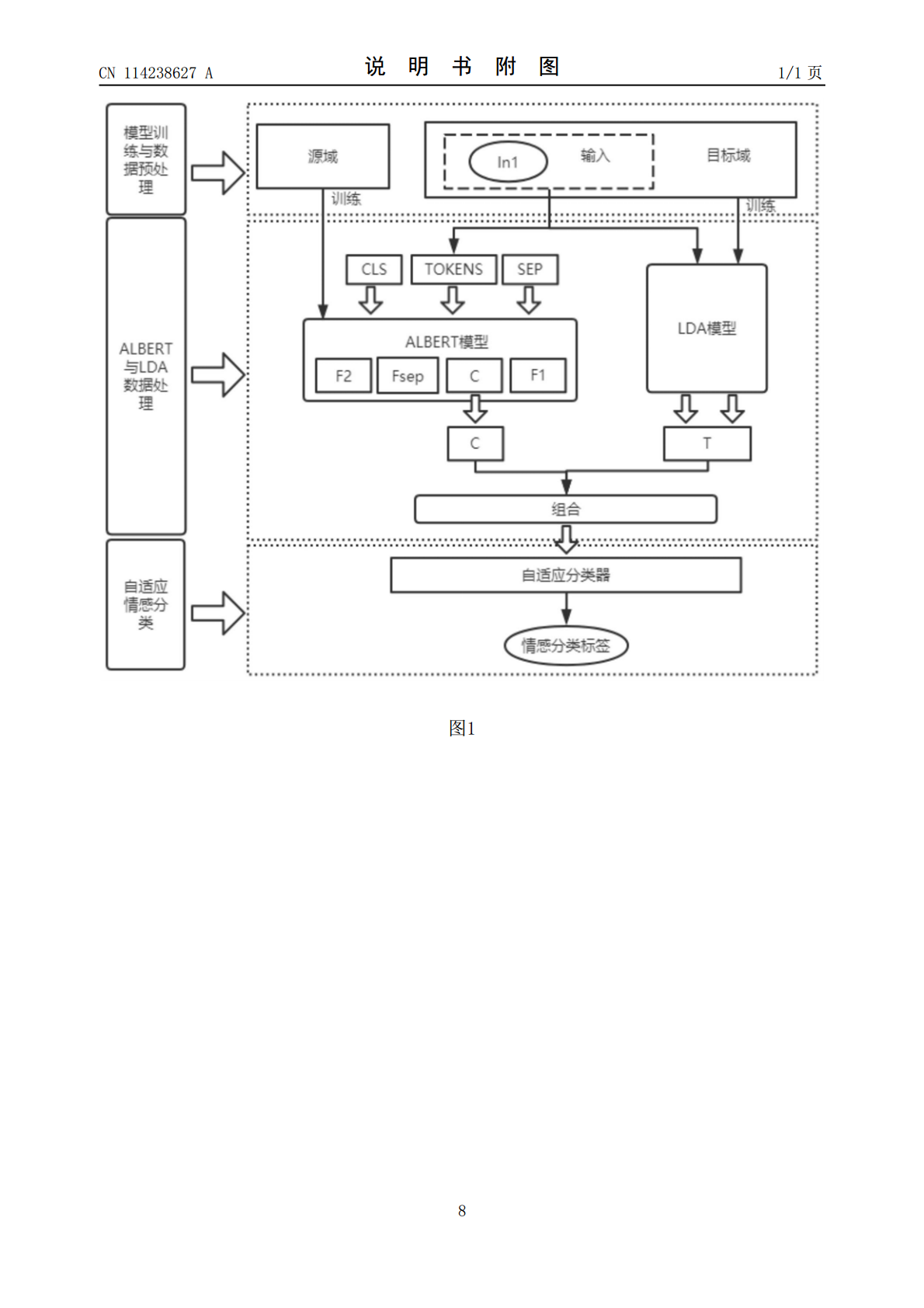
本发明公开了一种基于ALBERT和LDA的跨域情感分类方法,首先进行模型训练与数据的预处理,使用训练数据集对ALBERT模型进行训练,得到用于对目标领域数据检测的ALBERT模型,同时,使用目标领域的数据集进行主题模型训练,得到用于文本主题信息提取的LDA模型;随后针对输入的文本信息进行处理,使用ALBERT对该数据进行处理,得到处理后的向量,同时将该文本输入至LDA模型进行主题信息检测,得到文本主题信息,将处理后的向量与文本主题信息进行结合,输入到一个自适应分类器之中进行情感分类,最终输出情感分类标签。

一种基于注意力机制与强化学习的跨域情感分类方法.pdf
为解决不同领域标记数据缺失下的情感分类的问题,本发明提出了一种基于注意力机制与强化学习的跨域情感分类方法。首先,针对源域标记数据以及目标域无标记数据进行预处理,随后训练大规模语言模型BERT,并借助于注意力机制进行数据项中情感特征的提取。接着,基于强化学习思路应用随机策略进行特征选择,并根据计算得到的延迟奖励进行策略优化。最终,使用最优的情感分类策略实现跨域情感分类。本发明提升了源域中标记数据的使用率,并有效实现了跨域情感分类,减少了人工标记的成本。

一种跨域图像分类方法.pdf
本发明公开一种跨域图像分类方法,该方法用视觉特征提取器提取待分类目标域图像的初始视觉特征,并利用初始视觉特征构建领域对齐损失函数、类别对齐损失函数和结构对齐损失函数,再构建分类器,最后利用视觉特征提取器和分类器获得待分类的目标域图像的分类结果。该方案利用领域对齐损失函数、类别对齐损失函数和结构对齐损失函数来减小待分类目标域图像各个领域之间的差异,提高对跨域图像的分类精度。

一种基于原型对比自训练的跨域图像分类方法.pdf
本发明公开了一种基于原型对比自训练的跨域图像分类方法。本发明包括如下步骤:1)通过域不变特征学习方法,获得跨域图像分类模型;2)利用当前最新的跨域图像分类模型预测目标域上图像的伪标签,使用每个批次的数据不断更新每个类别的原型并计算对比损失;3)将分类损失和对比损失结合构成目标函数进行训练,优化更新特征抽取网络与跨域图像分类网络,再回到步骤2)循环执行。本发明将原型对比学习融入到自训练中,通过将目标域中无标签图像数据的分布结构编码进自训练框架中,并在自学习的过程中完全放弃掉源数据,有效解决了域不变表征学习与

基于嵌入学习的近重复视频检索和跨域情感分类研究的开题报告.docx
基于嵌入学习的近重复视频检索和跨域情感分类研究的开题报告一、研究背景和目的随着互联网视频的快速发展,视频数量呈爆炸式增长。虽然视频数量的增加给用户带来了更多的选择,但是也对视频检索和推荐的技术提出了更高的要求。其中,近重复视频检索和跨域情感分类是视频内容分析的两个重要研究方向。近重复视频检索是指根据视频内容相似度,找出相似或相同的视频,通常用于版权保护、视频剪辑和视频推荐等应用。跨域情感分类是指将一种领域的情感分类模型泛化到其他领域,通常用于跨语言和跨领域的情感分析等应用。这两个问题在实际应用中十分常见,