
基于多视角的卷积神经网络的图像去噪方法.pdf

和裕****az


1/10

2/10

3/10

4/10

5/10

6/10
7/10
8/10

9/10

10/10
在线预览结束,喜欢就下载吧,查找使用更方便
相关资料

基于多视角的卷积神经网络的图像去噪方法.pdf
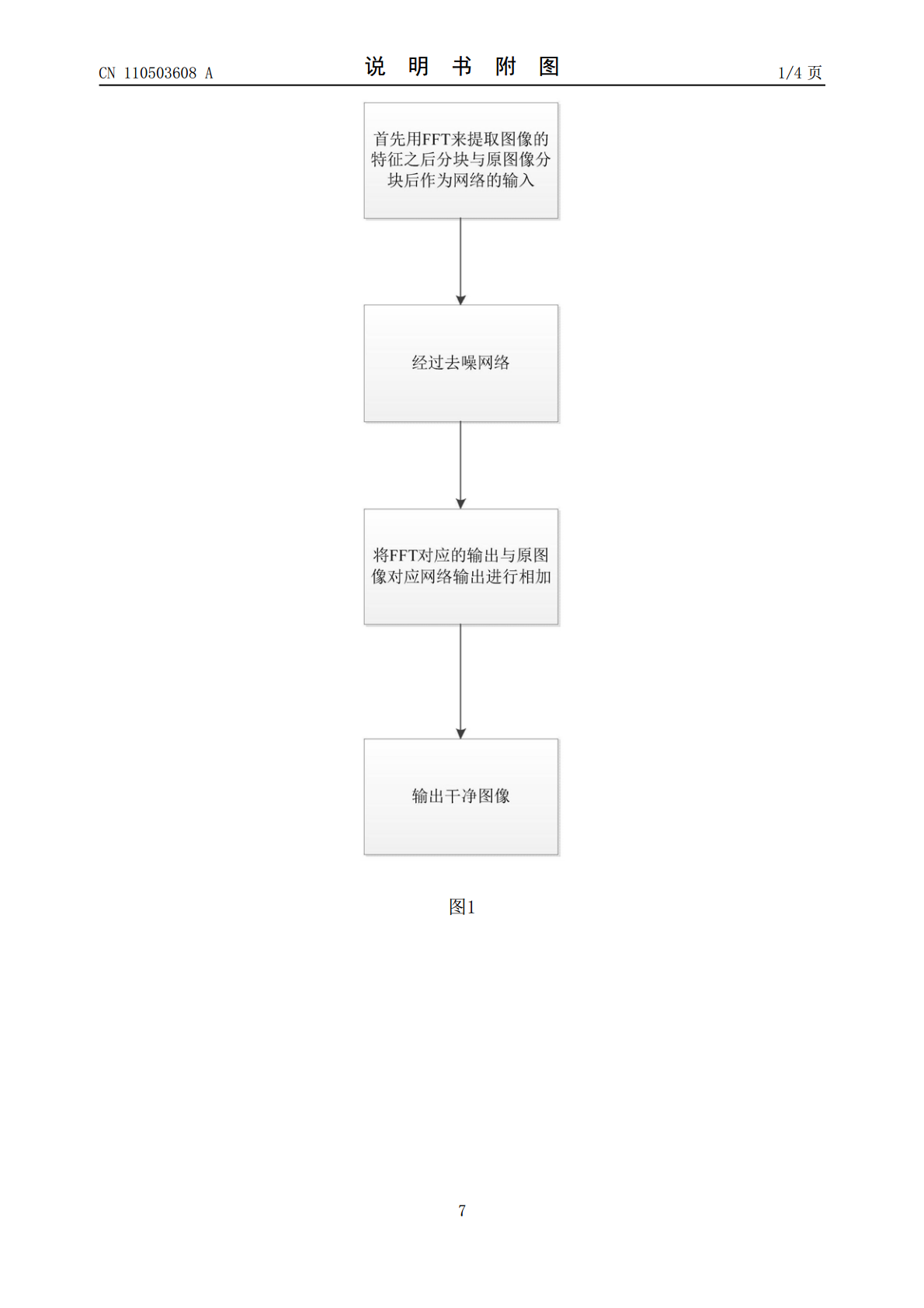
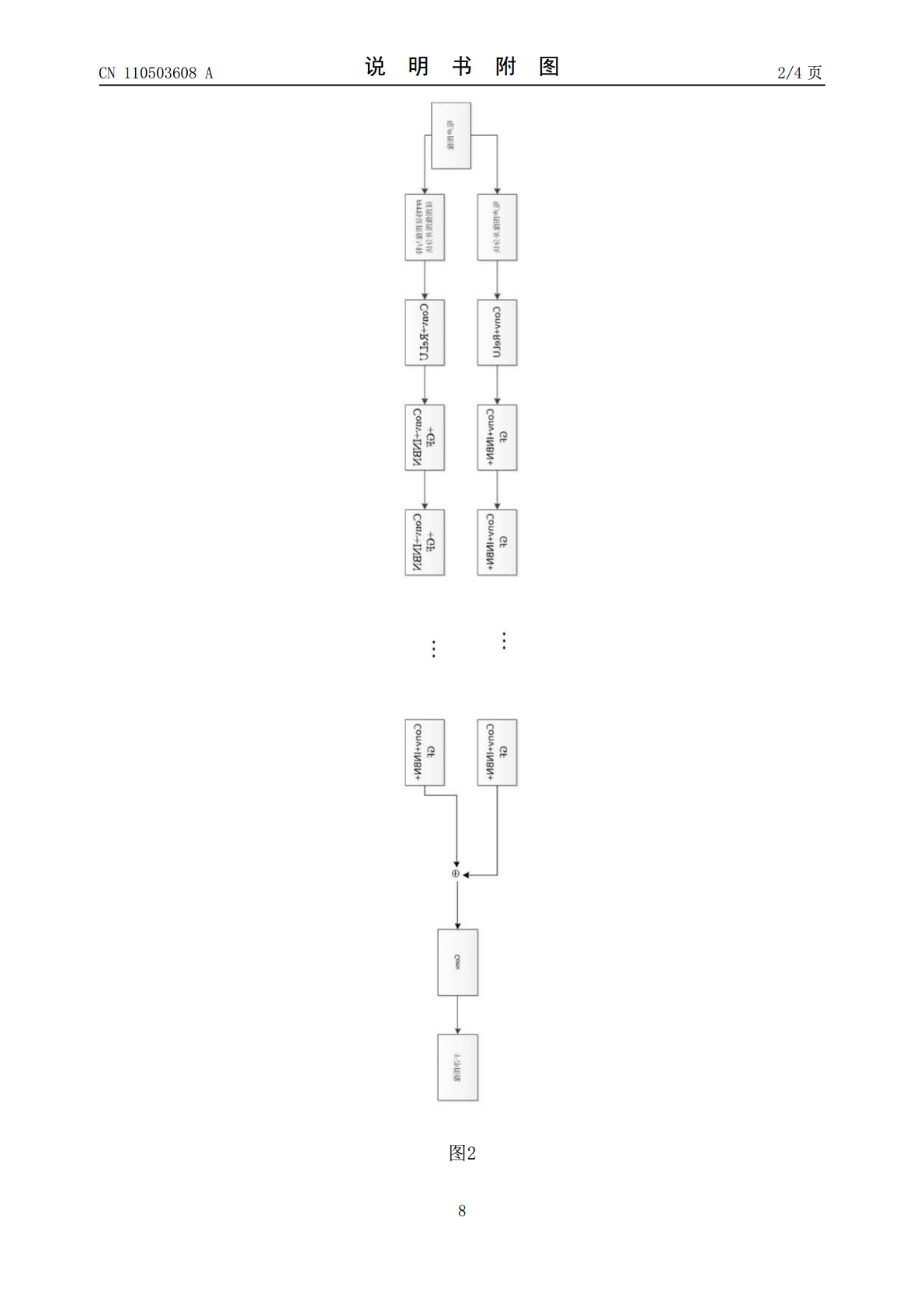
本发明公开了一种基于多视角的卷积神经网络的图像去噪方法。本发明用INBN技术代替了BN来加快去噪网络的收敛;该方法能有效地补就BN的不足和加快网络收敛,能处理真实噪声图像、盲噪声以及高斯噪声。本发明仅仅用20层的网络来进行去噪,减少网络的计算代价。此外,本发明用一种新的技术GF技术来更好把线性数据变换为非线性的数据;用Smooth函数来更好地训练去噪模型。此外,它采用多视角的特征融合来增强网络性能。本发明对于现实中灾难救援、航空探险与医疗诊病具有重要意义。

基于多尺度卷积组与并行的卷积神经网络图像去噪方法.pdf
本发明公开了基于多尺度卷积组与并行的卷积神经网络图像去噪方法,具体为:步骤1、准备训练集,选择合适的数据集作为训练集中的原始图像,并对其进行预处理操作,采用高斯白噪声模拟真实噪声并加入到原始图像中,作为与之对应的噪声图像;步骤2、构建网络模型,结合多尺度卷积组与并行的卷积网络方式搭建网络模型;步骤3、根据步骤2中所构建的网络模型设置网络的超参数、损失函数和优化算法;步骤4、进行网络训练,使用步骤2中的构建网络模型来分别训练单噪声训练集和多噪声训练集,来得到多个与训练集相对应的网络模型;步骤5、测试网络性能

基于残差学习的卷积神经网络医学CT图像去噪方法.pdf
基于残差学习的卷积神经网络医学CT图像去噪,具体步骤如下:步骤1)构建医学CT图像模型;步骤2)构建神经网络模型;步骤3)训练网络;步骤4)更新参数;步骤5)医学CT图像去噪,向构建好的网络模型中输入含噪声的医学CT图像,网络输出去除噪声后的医学CT图像。本发明具有以下优点:提出了结合深度学习中卷积神经网络方面的知识进行医学CT图像去噪;采用残差学习的方式来近似学习图像中的噪声,具有很好的针对性,同时提升神经网络的训练效率;采用卷积神经网络和残差学习的方法,能够更好的学习图像中的特征信息,在图像去噪的过程

一种基于卷积神经网络的光场图像去噪方法.pdf
本发明公开了一种基于卷积神经网络的光场图像去噪方法,其首先将4D光场图像分别重组为子孔径图像和微透镜阵列图像;之后构建初始堆栈空间卷积块和初始角度卷积块以分别对子孔径图像和微透镜阵列图像提取空间特征和角度特征;然后引入空间角度联合编码器组来建模空间特征和角度特征间的信息补偿关系并提高特征的表达能力;基于提取的空间特征和角度特征,构建空间角度特征融合器组以充分利用特征来丰富重建去噪光场图像的细节信息;最后利用构建的解码器来将空间角度特征融合器组输出的融合特征重建为去噪光场图像;优点是有效去除光场图像中存在的

一种基于可变形卷积神经网络的图像去噪方法.pdf
本发明公开了一种基于可变形卷积神经网络的图像去噪方法,所述方法包括构建可变形卷积神经网络模型,构建完成的可变形卷积神经网络模型包括两个子网络模型,分别为用于图像去噪的第一网络模型,以及用于辅助第一网络模型进行图像去噪的第二网络模型。然后再训练构建完成的可变形卷积神经网络模型,最后利用训练完成的可变形卷积神经网络模型进行图像去噪。本发明公开的图像去噪方法有效改进了目前基于神经网络的去噪方法中存在的图像失真或去噪效果不良的问题。