
一种基于单源点检测的欠定盲源语音信号分离的方法.pdf

琰琬****买买


1/9

2/9

3/9

4/9

5/9

6/9
7/9
8/9
9/9
在线预览结束,喜欢就下载吧,查找使用更方便
相关资料

一种基于单源点检测的欠定盲源语音信号分离的方法.pdf
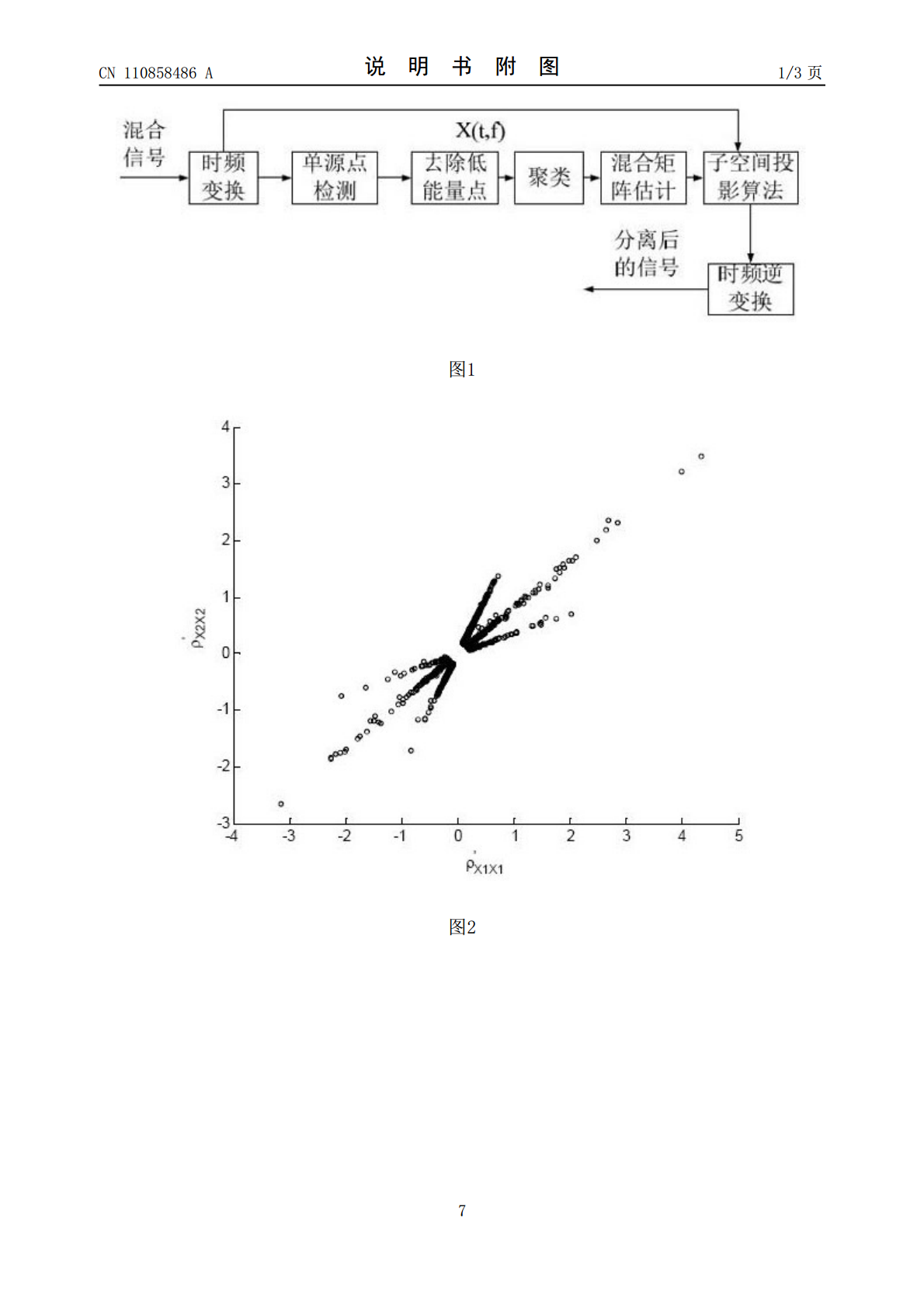
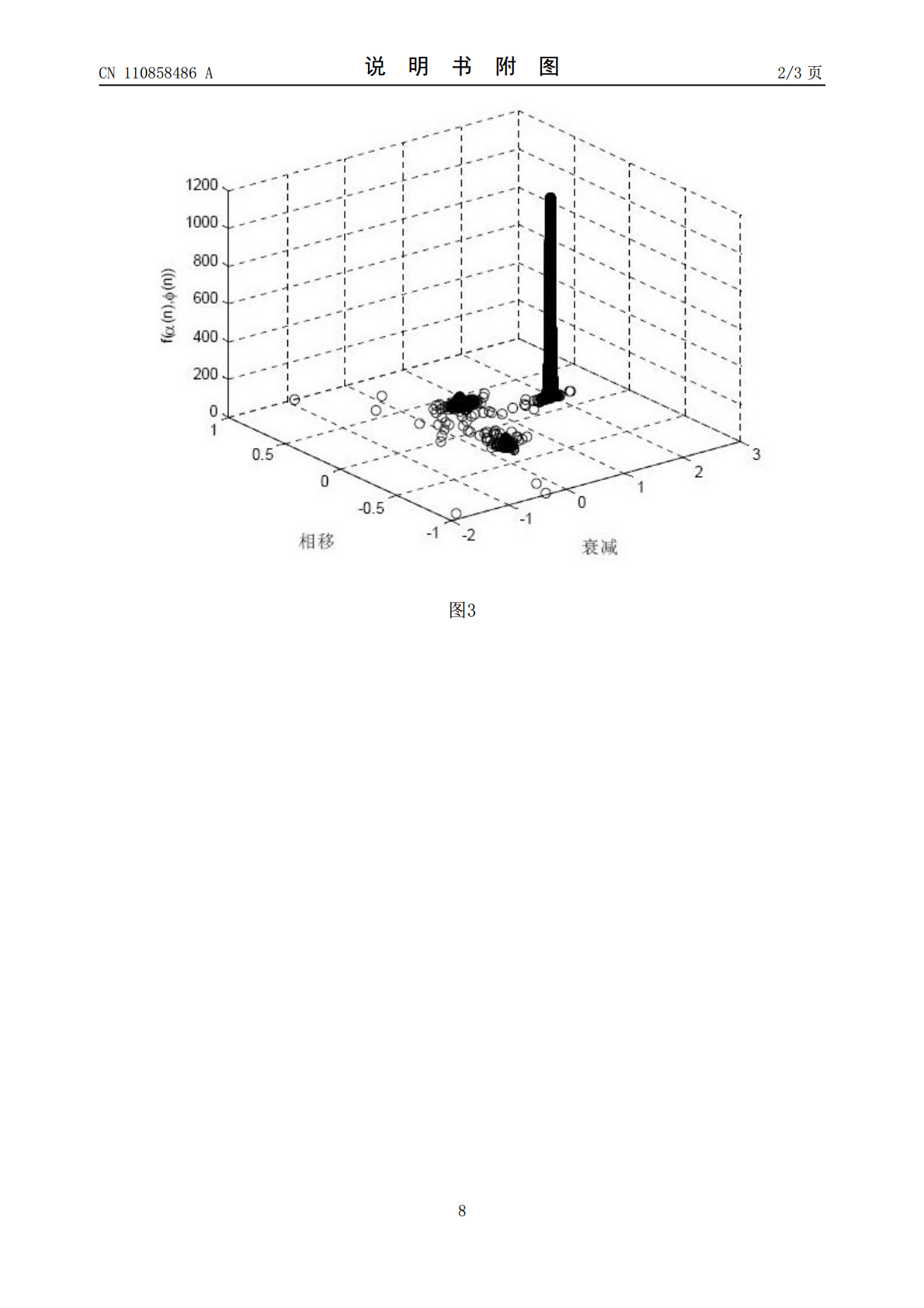
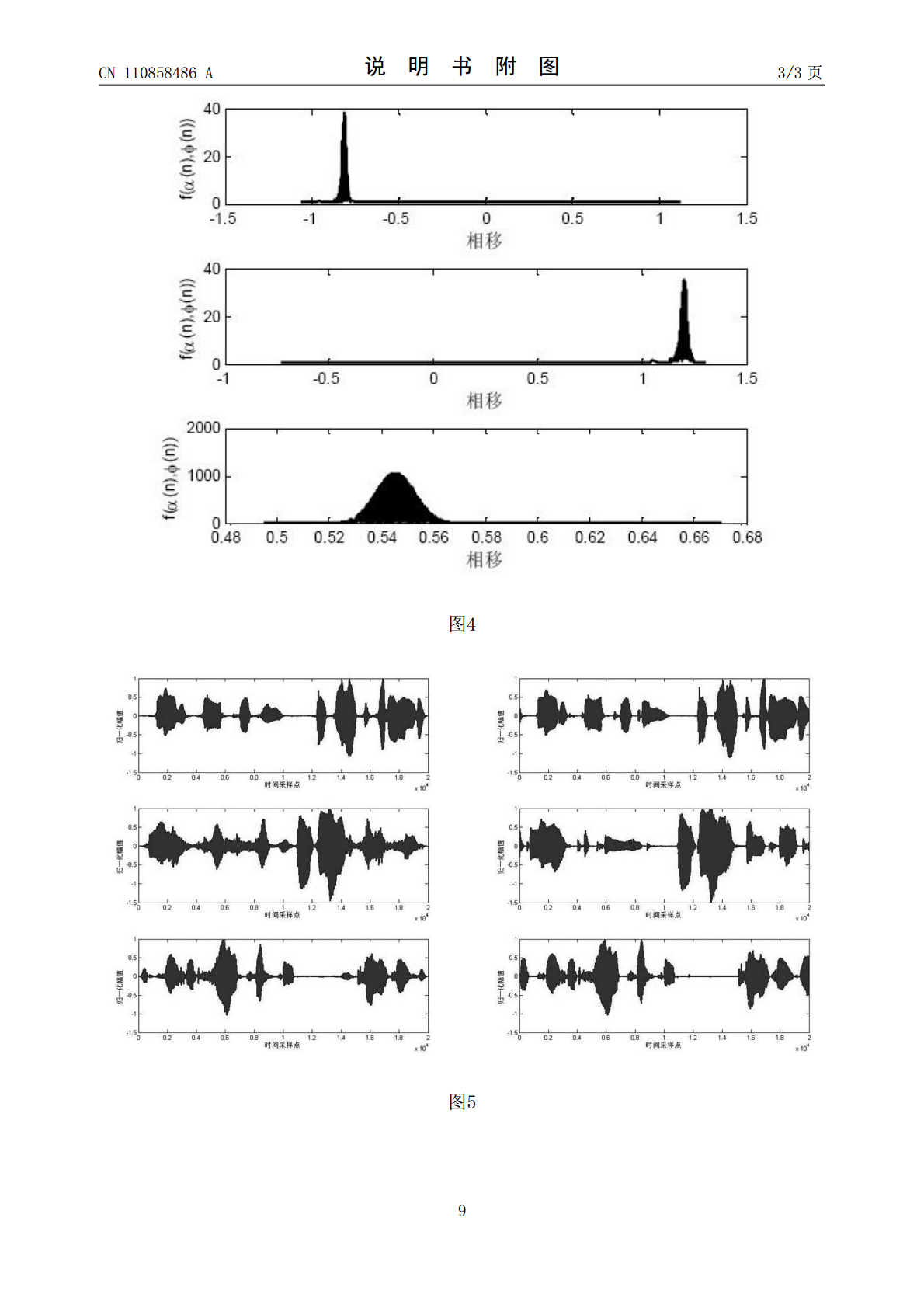
本发明提供了一种基于单源点检测的欠定盲源语音信号分离的方法,包括以下步骤:首先将线型麦克风阵列放于源信号的远场,得到多组接收信号数据;然后将接收信号数据进行时频域分析,构建时频域信号散点图;对每个点的横纵坐标作比值得到一组数据,进行聚类得到幅度的衰减参数;利用势函数聚类方法,得到势函数—衰减参数—时延参数三维散点图。利用子空间映射的方法,混合矩阵下完成源语音信号的恢复。本发明的核心内容在于利用盲源分离中的稀疏成分分析技术提出一种基于单源点检测的欠定盲源语音信号分离的方法,应用本发明可以在一定含噪环境下,对

基于单源点检测的欠定盲源分离方法.pdf
本发明公开了基于单源点检测的欠定盲源分离方法,首先将待分析的观测信号进行短时傅里叶变换得到相应的时频域复矩阵。然后将每个观测信号的时频复矩阵向量化并归一化。利用向量的余弦夹角准则检测出归一化时频矩阵中所有相等的列向量,这些提取的列向量即为单源点。然后对已提取的单源点进行层次聚类,得到聚类中心,每个类别的中心对应混合矩阵的一列,进而实现混合矩阵的估计。最后利用估计的混合矩阵,通过最小二乘法实现所有源在所有时频点的时频估计,再通过时频逆变换得到源的时域形式。本发明提出的方法考虑了不同单源点之间的线性关系,而且

一种基于复角检测的欠定盲源分离中的时频单源点提取方法.pdf
本发明属于盲信号分离技术领域,尤其涉及一种基于复角检测的欠定盲源分离中的时频单源点提取方法。本发明包括:从接收传感器获取经过瞬时混合后的源信号即观测信号;忽略噪声的影响,计算观测信号的空间时频分布;计算时频域各传感器接收信号的复角;计算两传感器接收信号的复角的反正切函数差值;取时频单源点集合中的时频点,通过自适应层次聚类的方法去除噪声。本发明提供的方法降低了对源信号稀疏性的要求,提高了时频单源点的提取精度,使得本发明可以解决源信号在时频域均混叠条件下的欠定盲源分离中时频单源点的提取问题。

基于稀疏化理论的欠定生猪盲源信号分离方法.pdf
本发明公开了一种基于稀疏化理论的欠定生猪盲源信号分离方法,包括:获取混合生猪音频信号;构建欠定盲源分离模型;基于所述欠定盲源分离模型对所述混合生猪音频信号进行稀疏化以及单源点提取,获取单源点;基于所述单源点获取估算混合矩阵;基于所述欠定盲源分离模型与所述估算混合矩阵获取源信号;对所述源信号的音频质量进行测量。本发明能够较为有效地分理出混合猪声信号的各源信号分量,为混合生猪音频的特征提取提供了新方案,有助于生猪的健康养殖。

基于密度的欠定盲源分离方法.pdf
本发明公开了一种基于密度的欠定盲源分离方法,主要解决现有技术计算复杂度高,易受初始值影响,需给定源信号个数的问题。其实现步骤是:对观测信号去掉低能量采样数据后投影到单位右半超球面上;计算所有投影点的密度参数,删除密度较小的投影点;利用改进的K-均值聚类算法对剩余投影点进行聚类,确定最佳聚类个数和聚类中心;去掉包含数据对象个数很少的聚类,剩余聚类个数为源信号个数的估计值,对应的聚类中心为混合矩阵各个列矢量的估计值;根据观测信号和估计出的混合矩阵,采用线性规划法恢复源信号。本发明降低了计算复杂度,减小了初始值