
一种基于WaveRNN的端到端语音合成方法.pdf

玉环****找我


1/10

2/10

3/10

4/10

5/10

6/10

7/10

8/10

9/10
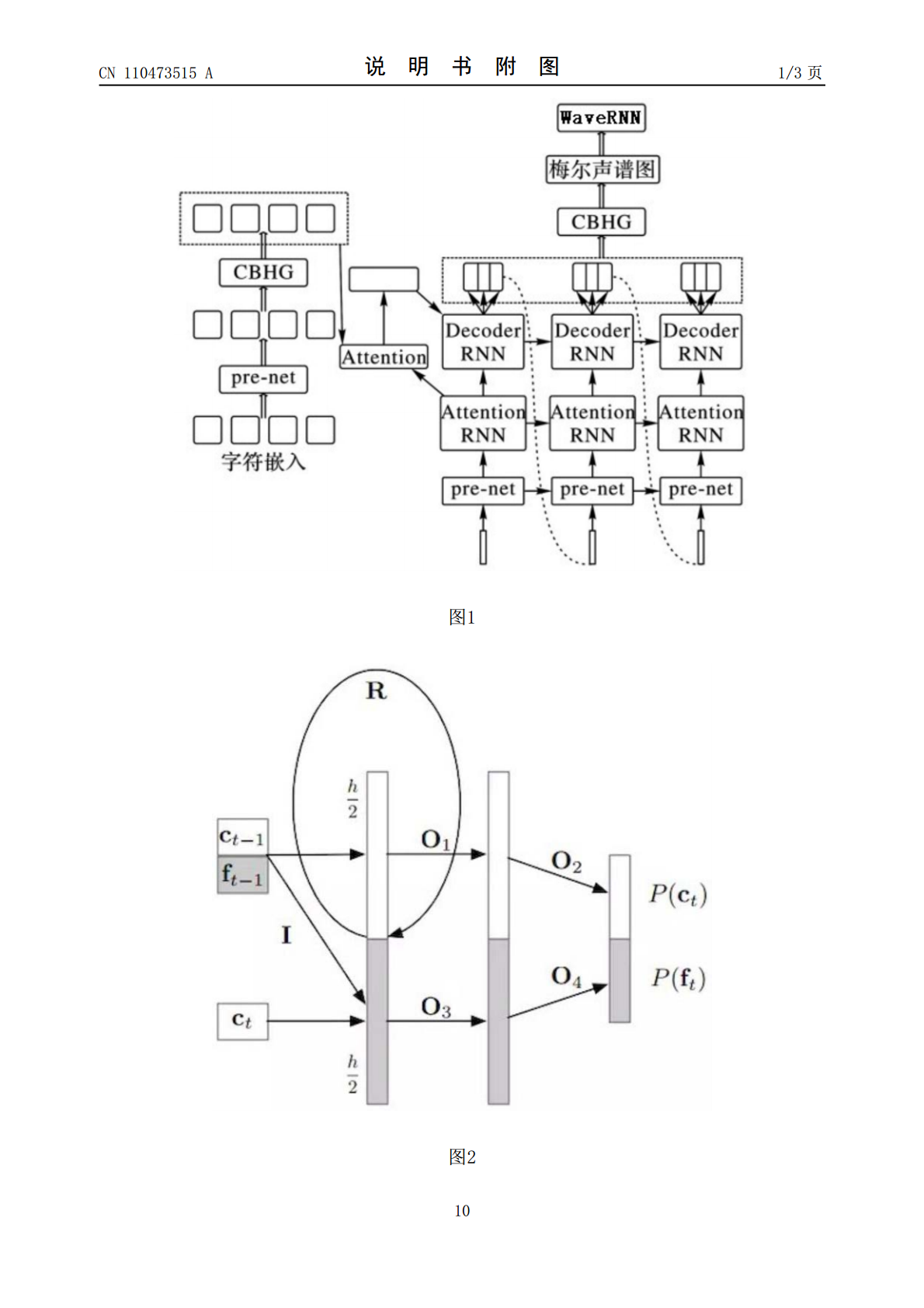
10/10
亲,该文档总共12页,到这已经超出免费预览范围,如果喜欢就直接下载吧~
相关资料

一种基于WaveRNN的端到端语音合成方法.pdf
本发明公开了一种基于WaveRNN的端到端语音合成方法,包括如下具体步骤:S1、前端处理,标注语言形成神经网络深度学习的音频特征向量,音频特征向量与文本字符对应;S2、文本字符输入;本发明提供一种基于WaveRNN的端到端语音合成方法,采用WaveRNN架构作为语音生成器,重构损失的相位信息,梅尔频谱特征逆变换为时域波形样本,进而生成语音提升合成语音的质量,合成的语音保真度较高,本发明中WaveRNN由称为双softmax层组成组成;WaveRNN其具有与最先进的WaveNet模型的质量匹配的双softm

一种端到端语音合成方法和装置.pdf
本发明涉及一种端到端语音合成方法,所述方法具体包括:构建包括HAE、HCE、HAD的层级条件变分自编码器模型;以最大化证据下界为训练目标,训练所述模型;合成语音波形。还涉及了装置,包括HAE、HCE、HAD、训练模块;其中,HAE包括:帧级、音素级、子词级、词级、句子级五级语音编码器,第一仿射模块;HCE包括:语言学表征提取模块、子词级、词级、句子级三级文本编码器;HAD包括:句子级、词级、子词级、音素级、帧级五级解码器,第二仿射模块。本发明的方法和装置,提升了合成语音的整体质量、自然性,以及韵律表现力。

一种基于跳跃编码器的并行端到端语音合成方法.pdf
本发明涉及语音合成技术领域,具体涉及一种基于跳跃编码器的并行端到端语音合成方法,包括以下步骤:步骤一:将文本与韵律标记一起输入到编码器模块;步骤二:将编码器的输出输入到跳跃编码器,跳过输出序列中韵律标记对应时间步的特征,保留文本内容对应的隐特征;步骤三:通过FastSpeech的时长模型对得到的文本隐特征进行扩充;步骤四:将跳跃编码器的输出输入到FastSpeech基于Transformer的解码器实现并行化的解码,得到合成语音的频谱特征;步骤五:使用声码器将频谱特征映射为声音波形,得到合成的语音。本发明

一种基于对比学习的端到端音障语音识别方法.pdf
本发明公开了一种基于对比学习的端到端音障语音识别方法,该方法具备语音识别能力前需要使用大量正常发音数据预训练得到一个基本模型,再迁移到音障语音识别的任务中。在训练完成后,本方法就有了音障语音识别的能力。本发明首先对音障语音数据进行频谱图上的数据增强,再通过Transformer模型中的编码器提取隐层信息,然后该隐层信息经过投影模块被提取出低维的隐表示。最后本方法在隐表示所在的低维隐空间上进行对比损失的计算。在解码过程中,解码器直接使用隐层信息进行解码。本发明的创新点在于将对比学习与Transformer模

基于端到端模型的混合语音识别系统及方法.pdf
本发明涉及一种基于端到端模型的混合语音识别系统及方法,包括特征提取模块、语言模型、基于端到端模型的声学模型、解码器、词图重估模块以及输出模块。本发明采用声学语言端到端建模技术,对海量语音数据进行建模,并将端到端模型的编码网络作为声学模型,嵌入到混合语音识别系统中,不仅进一步提高了语音识别准确率,而且解决了纯端到端语音识别系统在项目中难以做定制化的问题。另外,本发明在端到端模型的编码网络的基础上,继续做鉴别性声学模型训练(SMBR、MPE等),可以进一步提高识别准确率。