
一种基于特征融合的语音识别方法及装置.pdf

沛芹****ng


1/9

2/9

3/9

4/9

5/9

6/9

7/9

8/9
9/9
在线预览结束,喜欢就下载吧,查找使用更方便
相关资料

一种基于特征融合的语音识别方法及装置.pdf
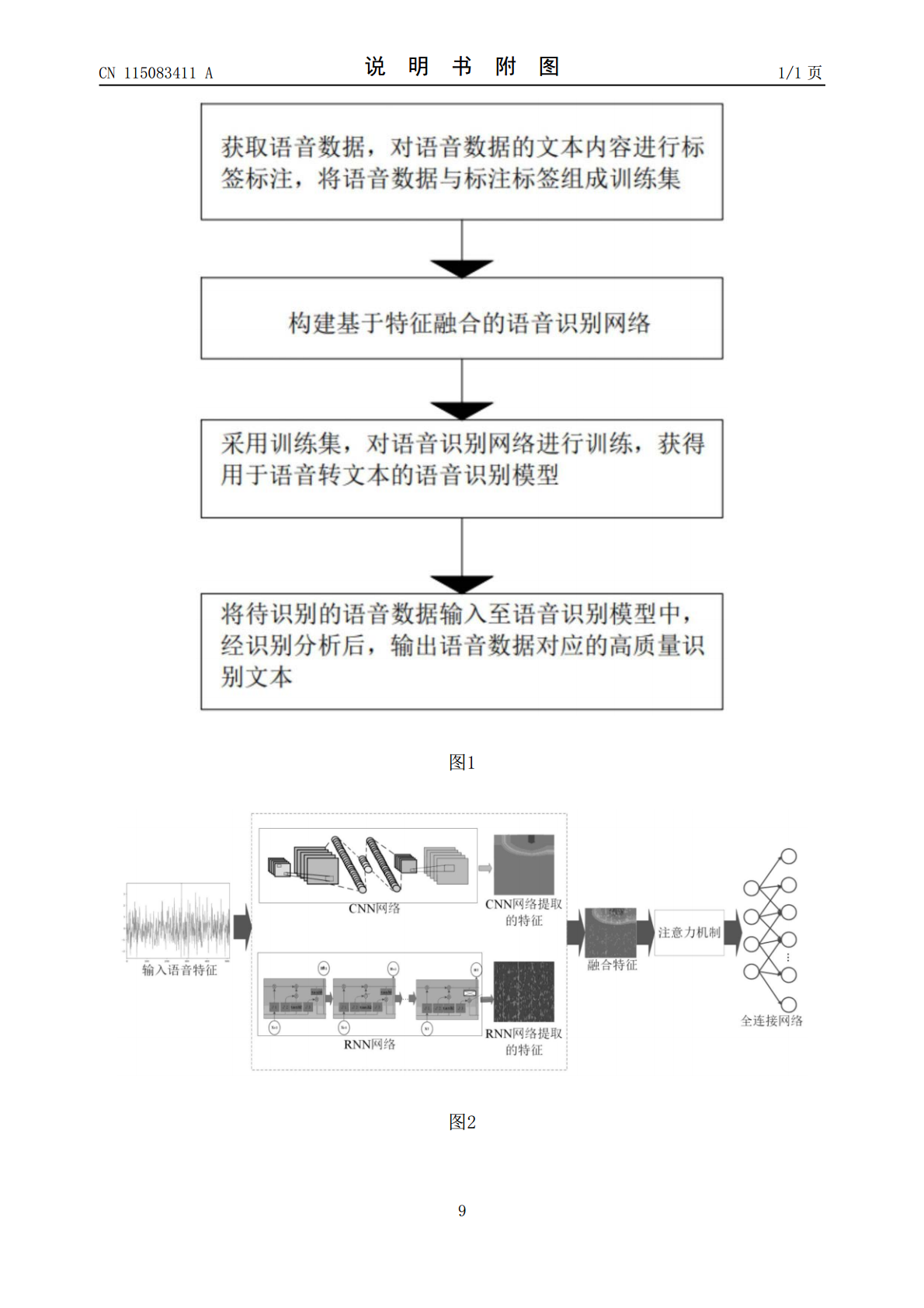
本发明公开了一种基于特征融合的语音识别方法,包括:步骤1、获取语音数据,对所述语音数据的文本内容进行标签标注,将语音数据与标注标签组成训练集;步骤2、构建基于特征融合的语音识别网络,所述语音识别网络包括特征提取模块,数据处理模块,特征融合模块,注意力模块以及识别模块;步骤3、采用步骤1的训练集,对语音识别网络进行训练,获得用于语音转文本的语音识别模型;步骤4、将待识别的语音数据输入至步骤3获得的语音识别模型,经识别分析后,输出语音数据对应的高质量识别文本。本发明还提供了一种语音识别装置。本发明提供的方法通

基于多运动特征融合的微表情识别方法及装置.pdf
本发明实施例提供了一种基于多运动特征融合的微表情识别方法及装置、电子设备和存储介质,所述微表情识别方法,通过将目标人物的面部表情图像序列进行预处理;通过多路卷积神经网络模型分别对预处理过的图像进行特征提取,并利用长短期记忆网络模型提取时序特征进行进行分类训练得到人脸识别模型进行目标图像中的人脸微表情识别。采用卷积神经网络和长短期记忆网络模型结合的方式,通过前面的卷积网络层来提取微表情的静态特征,省去了传统机器学习方法,需要人工提取特征的过程,简化了特征提取的工作,能够准确的识别微表情。

基于特征融合的文本识别方法、装置、设备及存储介质.pdf
本发明涉及人工智能领域,公开了基于特征融合的文本识别方法、装置、设备及存储介质,用于提高文本识别的准确率。调用预置的神经网络组对待识别医疗图像进行特征提取,生成医疗局部特征图像和医疗全局特征图像,并调用预置的加权求和函数对所述医疗局部特征图像和所述医疗全局特征图像进行特征融合,生成目标医疗融合特征图像;调用预置的双向双层循环神经网络对所述目标医疗融合特征图像进行字符集提取,生成医疗分类字符集,并基于医疗分类字符集与预置的时序分类算法进行对齐解码,生成目标医疗文本。此外,本发明还涉及区块链技术,待识别医疗图

一种生成声学特征、语音模型训练、语音识别方法及装置.pdf
本申请实施例公开了一种生成声学特征、语音模型训练、语音识别方法及装置,通过获取当前语音帧的声学信息向量和当前语音帧的信息量权重,并根据上一语音帧对应的已累积信息量权重、当前语音帧对应的保留率以及当前语音帧的信息量权重,能够得到当前语音帧对应的已累积信息量权重。保留率为1与泄漏率之差。利用泄漏率调整当前语音帧对应的已累积信息量权重和当前语音帧对应的整合声学信息向量,能够降低信息量权重较小的语音帧对于整合声学信息向量的影响,提高信息量权重较大的语音帧的声学信息向量在整合声学信息向量中所占的比重,得到的整合声学

一种基于动静特征融合的人脸识别方法.pdf
本发明公开了一种基于动静特征融合的人脸识别方法,尤其是基于综合的静态特征和动态特征的人脸识别方法;静态特征侧重全局轮廓,将人脸图像特征看做高维特征,通过线性和非线性变换映射到低维的子空间中,从而在低维空间中得到该原始样本的特征进行分类,动态特征侧重局部变化,主要根据人脸的表情,如微笑,沮丧等,通过提取人脸肌肉变化的动态特征,得到一组肌肉变化与时间的特征函数,从而进行精确识别和分类,实现人脸识别精度的提高。